Editor’s note: The one-in-a-million bug detailed below has never been reported by customers of Cockroach Labs. It was autofiled by Sentry’s crash reporting module, which led us on a long journey to uncover its root cause(s). The story below details our investigation into and ultimate resolution of said bug.
Background: Nondeterminism
Nondeterminism–the property of being in any of the possible next states, is a double-edged sword. In Computer Science (CS), the notion of nondeterminism is instrumental to managing complexity of reasoning about the state space. The earliest uses of nondeterminism appear in [Chomsky, 1959] and [Rabin and Scott, 1959]. The former gave us succinct context-free grammars (CFG), e.g., arithmetic expressions,
S ::= x | y | z | S + S | S * S | (S)
The latter gave us non-deterministic finite automata (NFAs), aka regular expressions. Both CFGs and NFAs are fundamental concepts, known virtually to any CS grad.
And of course, who can forget the elusive problem of P = NP [Cook, 1971 and Levin, 1973], and the eternal search for taming NP-completeness? As an example, testing serializability of a given history of committed transactions is NP-complete (see Testing Distributed Systems for Linearizability). However, if we’re given a total (per-object) order, the verification problem is now in P. Indeed, the Elle checker runs in linear time.
In software verification, nondeterminism allows techniques like symbolic model checking (SMC) in cases where exhaustive state enumeration is infeasible, such as pretty much any modern distributed system like CockroachDB. For a recent, large-scale application of SMC, see Model checking boot code from AWS data centers. Nondeterminism also makes TLA+ more expressive. The one-in-a-million bug we discuss below is a byproduct of the implementation of the ParallelCommits.tla model.
Demonic Nondeterminism
While CS theoreticians mostly see the good side of nondeterminism, practitioners of distributed systems often fall prey to its bad side–(distributed) failure reproduction. Indeed as others have pointed out, “Nondeterminism makes the development of distributed systems difficult.”. Inability to reproduce bugs is one of the main reasons that distributed systems are notoriously hard to debug. Nondeterminism of this type is known as demonic. (Intuitively, “worst” possible action is chosen.) E.g., Go’s select statement behaves like Dijkstra’s guarded commands. Ignoring its demonic nondeterminism leads to bugs like this. (The bug is triggered when multiple goroutines execute inside the default clause.)
Despite decades of R&D improvements, there is an obvious gap in available tools to help debug and reproduce a “one-in-a-million” type of bug. Colloquially, we refer to such bugs whose probability of failure is extremely low; they typically require several, correlated internal state transitions, e.g., race conditions and/or intermittent (hardware) failure(s). Until recently, one such bug lurked in CockroachDB. Achieving world class resiliency is one of our highest product principles, and by enlisting the help of Antithesis, a startup from the founders of FoundationDB, we were able to track down and reproduce this most elusive bug, nearly deterministically! With additional instrumentation in the form of (distributed) traces, many reruns, and much log spelunking, a fix was merged, thanks to Alex Sarkesian, co-author of this post and former KV engineer at Cockroach Labs.
Without deterministic reproduction, conventional debugging and (stress) testing don’t yield an effective strategy; for “one-in-a-million” type of bug, it’s really no different than pure chance. Sadly, the state-of-the-art of deterministic debugging leaves much to be desired.
Below we review existing tools. Then, we describe our experience with Antithesis, a system for autonomous testing. We conclude with an intuitive description of the discovered bug and its fix. (See Appendix for technical details.)
Thesis
The idea behind “deterministic debugging” is not new. In Debug Determinism (~2011), the authors argue for, “a new determinism model premised on the idea that effective debugging entails reproducing the same failure and the same root cause as the original execution”. Conceptually, it’s exactly what we’re after; in practice, it’s hard to achieve. Let’s quickly review why and what’s currently available.
Sources of Nondeterminism
For a stateful, distributed system like CockroachDB, running on a wide variety of deployment environments, sources of nondeterminism can seem endless. Unexpected network delays, thread timings, and disk faults can conspire to manifest rare bugs hidden in the system, particularly in ways that can be nearly impossible to reliably reproduce, diagnose, and fix.
Flaky tests, particularly integration tests, can offer many examples of the bugs found due to this unexpected nondeterminism. Usual suspects like TCP port collision and out of file descriptors result due to resource limits; race conditions and timeouts are examples of scheduler non-determinism. (See A Survey of Flaky Tests and Reproducible Containers.)
Hardware (interrupts), clocks (e.g., clock_gettime), /dev/(u)random, and CPU instructions (e.g., RDRAND) are other examples. Beyond single address space, network is a major source of nondeterminism.
ptrace to the Rescue
ptrace is a system call that’s been around since Version 6 Unix (~1975). Originally added to support debugging with breakpoints, today it supports a whole gamut of applications such as syscall tracing (strace) and syscall record and replay (rr). In essence, ptrace allows to emulate any syscall by intercepting the original call and modifying its result(s). (See Liz Rice’s Demo strace in Go). Thus, nondeterministic syscalls, e.g., clock_gettime, can be emulated by their deterministic counterparts, e.g., using a logical clock.
In fact, ptrace, a logical clock, a single-threaded scheduler, and a RAM disk is roughly all you need for deterministic debugging on a single machine; beyond a single machine, network is a great non-determinizer. Note that a logical clock can be effectively derived from the precise CPU hardware performance counter–retired conditional branches (RCB).
History of Deterministic Debuggers

To our knowledge, deterministic debugging is fairly sparse and experimental. The above timeline depicts some of the noteworthy tools developed in the last two decades. While valgrind isn’t strictly deterministic, it implements a single-threaded (fair) scheduler. It served as an inspiration for rr. The more recent development is hermit which was inspired by dettrace.
rr is perhaps the most widely known deterministic debugger. However, it’s only able to replay deterministically what was previously recorded; hermit, on the other hand, can deterministically execute any binary. (That is, under rr, a pair of runs of the same binary and input would yield two different recordings; see Explanation.)
At this time, the latter is highly experimental whereas the former is production-ready, assuming you can find a Cloud VM which exposes CPU perf. counters :)
Recall, Heisenberg’s Uncertainty Principle. Physicists discovered another bad side of nondeterminism way before computer scientists. Deterministic debuggers exhibit side-effects similar to quantum mechanics–deterministic recording alters original execution.
All of the above rely on ptrace, which incurs a significant overhead, 2-3x additional syscalls, plus context-switching. Using seccomp with eBPF can remove the overhead for non-emulated syscalls. The remaining overhead is still quite substantial although rr employs several optimization tricks, e.g., syscall buffering. Nevertheless, ptrace is a poorman’s deterministic debugger at best. Instead, what if determinism could be built directly into a hypervisor?
Antithesis
The Antithesis platform was inspired by FoundationDB, which is deeply embedded with a deterministic simulation framework. FoundationDB’s framework can simulate network and disk I/O, as well as inject faults. The simulation framework code is interleaved with the database code. E.g., here a corrupted key can be injected when FDB’s consistency checker is running inside the simulator. During simulation, an entire database cluster is running single-threaded in the same address space. Since all hardware I/O and non-deterministic syscalls are simulated, it’s effectively a whitebox, deterministic debugger. However, it’s not without limitations. E.g., third-party code like the RocksDB storage engine renders simulation non-deterministic.
While FoundationDB is unique in its inherent design to enable deterministic simulation testing, it is frequently far too complex to retrofit the large-scale code base of an existing database with such a system. The Antithesis platform solves this problem by using a deterministic hypervisor, thereby enabling virtually any binary to benefit from deterministic simulation testing!
Similar to FoundationDB, failure injection is built into the Antithesis platform. In running its autonomous tests, Antithesis will catch errors by monitoring for process failures, such as those caused by assertions like Go’s panic, as well as, by monitoring logs for errors and failures to maintain system invariants. These can be caught by providing regexes to fail on matching patterns of log messages. Intuitively, it runs many short experiments (scenarios), optimizing for a maximum amount of code (i.e. unique edges) explored over the course of a full test run, encountering a number of distinct failures. Roughly, each scenario denotes a simulator run under deterministically random failures. The example below shows thousands of scenarios executed over 25 hours.
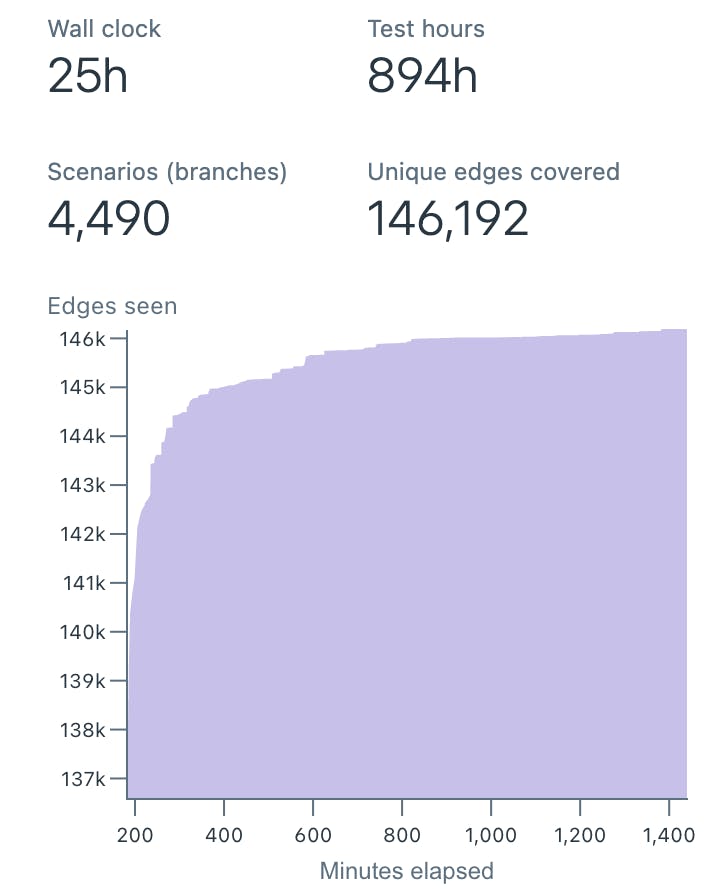
The Antithesis platform is more than just a deterministic simulator. It uses a fuzzer to find “interesting” scenarios. When available, code coverage instrumentation can provide further (optimization) guidance to the fuzzer, such that faults are injected to explore branches of the code not previously covered in the tests. In the above example, we can see a sharp increase in branches covered during the first ~5 hours. Then, coverage stabilizes as is often the case with distributed systems. (Absent any new failure, the same event loops are executed.)
Given what we now know about the Antithesis platform, we can succinctly describe it as Greybox Deterministic Simulator with Coverage-Guided Failure Injection. In layman’s terms it’s a marriage of a fuzzer and a deterministic debugger.
Synthesis
The one-in-a-million bug first showed up on our radar in 2021. None of our customers reported the issue but; it was autofiled by Sentry’s crash reporting module. The stacktrace revealed it to be a violated invariant–an undefined state. For this invariant, like many others, CockroachDB’s code asserts to ensure the invariant holds, using Go’s panic to crash the node and recover diagnostics for further troubleshooting. Unfortunately, besides the stacktrace and the anonymized cluster metadata, we didn’t have any actionable information. Furthermore, this failure mode never appeared in any of our extensive test runs.
In the investigation of these rare crash reports, engineers on our KV Team started to develop plausible theories; it appeared to implicate ambiguous errors which occur during retries of distributed SQL request batches. In 2023, we started evaluating the Antithesis platform. Fortuitously, one of the scenarios terminates in exactly the same, elusive state as seen in the log below.
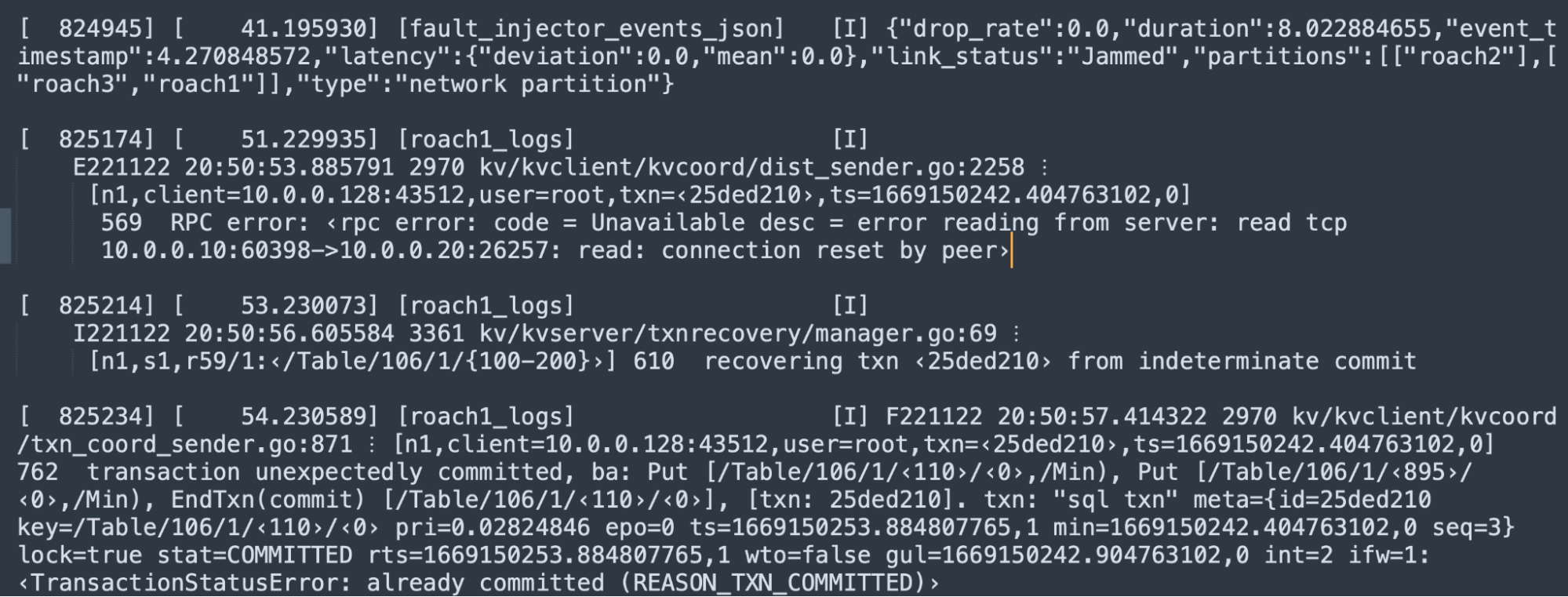
The error message “transaction unexpectedly committed” denotes a serious bug–it should not be possible to perform additional operations (such as writes) on an already committed transaction. Any data written by an atomically committed transaction can immediately be read by other transactions. Thus, any subsequent operations that could change that data would violate the transaction isolation model. Examining the above log output, we developed a few leads. (Recall, the crash reports gave us only a stacktrace without a full log.)
The failure message indicates the batch of inflight requests (ba), as well as, transaction record (txn), and the affected (key) ranges. Suspiciously, we see a batch with EndTxn(commit) and Put requests which, upon evaluation, is rejected due to being against an already committed transaction – particularly one previously noted as being in an indeterminate commit state. Immediately before the failure message is an indication of a “transaction recovery”. Lastly, we see an RPC error; though it is unclear if this is related, or simply a correlated symptom due to the simulation’s introduction of network interference. The RPC error is immediately preceded by a network failure injection message.
Armed with these new insights, the root cause should now be imminent, right? Not exactly. The transaction recovery message seemed to implicate the Parallel Commit protocol. However, the actual root cause analysis took a fairly long time, during which distributed traces and deterministic replays began to tease out the state machine behind the sufficient conditions for “transaction unexpectedly committed”. Many rinse-and-repeat cycles later, the root cause, its fix, and a reproducing unit test have emerged.
For an in-depth analysis of the root cause, see Appendix. The culprit, as it turns out, was an attempt to retry the ambiguous (or, “indeterminately committed”) write at a higher timestamp, which results in non-idempotency. More generally, we need to protect the transaction coordinator against non-idempotent replays of request batches that result in ambiguous failures (e.g., RPC error). That’s exactly what our fix implements. By explicitly tracking potentially non-idempotent replays, the transaction coordinator now responds with result is ambiguous error to the SQL client, if any replay fails the idempotency check, e.g., change of write timestamp.
This may not seem like the most graceful recovery; effectively, we’re shifting the burden of non-idempotent transaction retries to the SQL client. Sadly, CAP Theorem postulates we can’t have it all ways. In this case, owing to (partial) unavailability of the network, the transaction coordinator cannot verify, with any deterministic time bound, whether the transaction committed. We conclude by noting that while the Parallel Commit protocol was verified using TLA+, the model is an underapproximation of the actual implementation. Specifically, the TLA+ specification doesn’t model the above scenario.
Conclusion
Bugs are compounded by the number of distinct nodes operating in a distributed system, each providing their own sources of nondeterminism with thread timings, network conditions, hardware, and more. Finding and fixing these bugs requires new approaches to testing and debugging. At a recent seminar on Database Reliability and Robustness, industry practitioners summarized the state-of-the-art,
The current state-of-the-art is often simply rerunning a test a large number of times (e.g., 1000x), potentially after augmenting the system with additional logging, a slightly modified configuration, runtime sanitizers, or with changes to the system or test workload to increase the likelihood of perturbing the issue.
Like any emerging technology, the Antithesis platform is not without rough edges. Deterministic replay doesn’t immediately get you a reproduction, particularly across distinct code changes as you might see with a unit or integration test. In our experience, a significant amount of effort was invested in instrumenting the logs, as well as reasoning about injected failure states in order to recover the state machine which reproduces the bug. The rinse-and-repeat cycle means that a modified binary (with new instrumentation) may not always hit the same terminal state. Although, in practice determinism between runs is very high assuming the code changes are localized. (Recall that the retired conditional branches counter models a logical clock; thus, straight-line code tends to preserve determinism.)
Unlike rr, the Antithesis platform doesn’t support step-through debugging during replay. Thus, the ability to observe internal state outside of logging is missing. This feedback loop could reduce the rinse-and-repeat cycle and shorten the time to reproduction.
Despite the rough edges, the Antithesis platform remains a promising technology, with the potential to neutralize many hard-to-detect lurking bugs. It’s our belief that deterministic debugging is the future, and Antithesis is paving the way toward that goal.
Appendix
Root Cause Bird’s-eye View
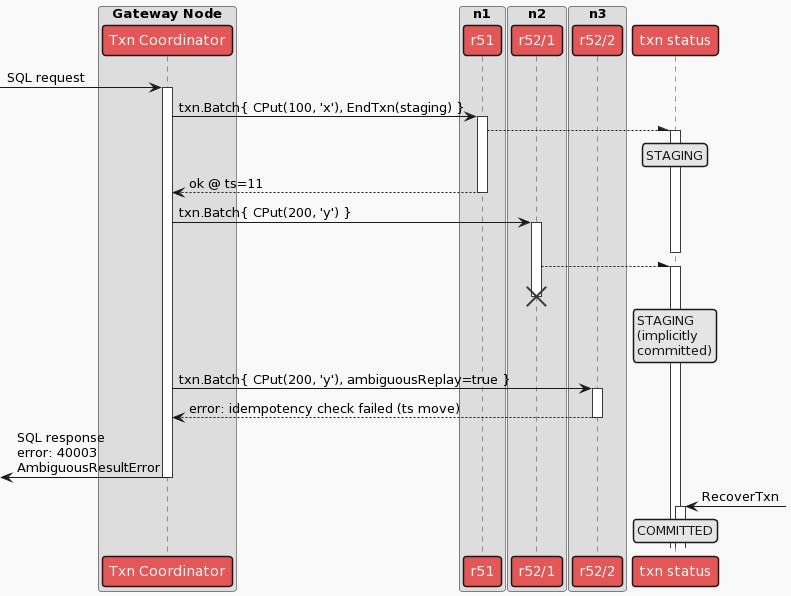
The sequence diagram below illustrates the bug scenario. The crux of the issue is an ambiguous write, denoted by the first attempt of txn.Batch{CPut(200, ‘y’)}. In other words, an RPC failure - the RPC performing the write on key y can time out or fail to respond, and if so the node performing the role of the transaction coordinator will not know if the first attempt succeeded to update ‘y’.
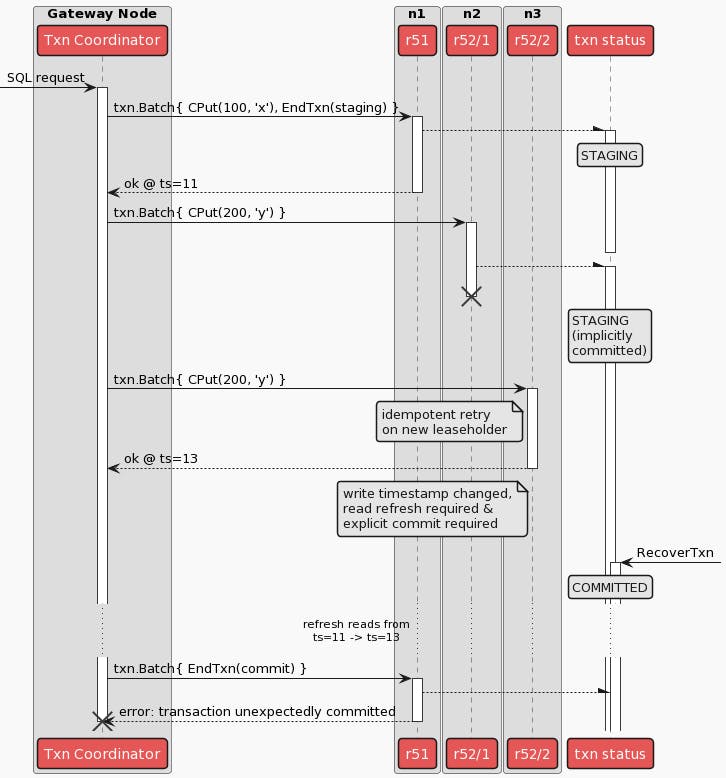
Immediately after the first write attempt fails due to the network failure, the leaseholder moves from n2 to n3. Subsequently, the second write attempt reaches a fresh leaseholder on n3, which results in requiring the transaction coordinator to move the transaction’s timestamp using something called a “read refresh”. The injected network failures also cause the transaction coordinator to miss heartbeats of the transaction’s record. Simultaneously, a contending transaction triggers a “transaction status recovery” process, which races with the transaction’s own retries. The former succeeds, marking the transaction record explicitly committed. The latter - i.e. the transaction’s retry after the ambiguous state - results in the transaction coordinator panicking.
Parallel Commits
In more technical detail, we can understand what caused this bug if we look deeper into the Parallel Commits protocol used in CockroachDB, with particular consideration for its Transaction Recovery mechanism and the race conditions that arise from it. Consider an implicit transaction like the following SQL statement:
INSERT INTO accounts (account_id, name) VALUES (100, ‘x’), (200, ‘y’)
In CockroachDB, rows are stored as key-value pairs, partitioned into many ranges - for example, we could have 100 <= account_id < 200 in one range, and 200 <= account_id < 300 in another, with leaseholders for these ranges spread across various nodes in the cluster. This requires usage of an explicit transaction record in order to ensure that the writes happen atomically; i.e. that they can be made visible to other reads at the same time, using an explicit transaction timestamp. This can look something like the following:
TransactionRecord{
Status: COMMITTED,
Timestamp: 5,
...
}
We’ll leave detailed description of the protocol to the previously mentioned blog post, however in short: while a traditional two-phase commit (2PC) makes writes visible by marking a transaction record as COMMITTED, and does so only after all writes have been acknowledged, CockroachDB’s Parallel Commits protocol works a bit differently. In addition to writes being visible once their transaction record is marked explicitly as COMMITTED, it also introduces a new state known as implicitly committed, where a transaction’s writes can be read if the reader can verify that all writes have been acknowledged. This looks instead like the following:
TransactionRecord{
Status: STAGING,
Timestamp: 30,
Writes: []Key{100, 200, ...},
...
}
This allows the transaction coordinator to write the transaction record in parallel with the transaction’s writes, and instead leaves the final step of marking the transaction as explicitly COMMITTED as post-transaction follow-up work that can happen asynchronously, decreasing transaction latency experienced by clients and improving throughput. In terms of CockroachDB’s underlying Key-Value Storage (KV) Operations, this process can look something like the following:
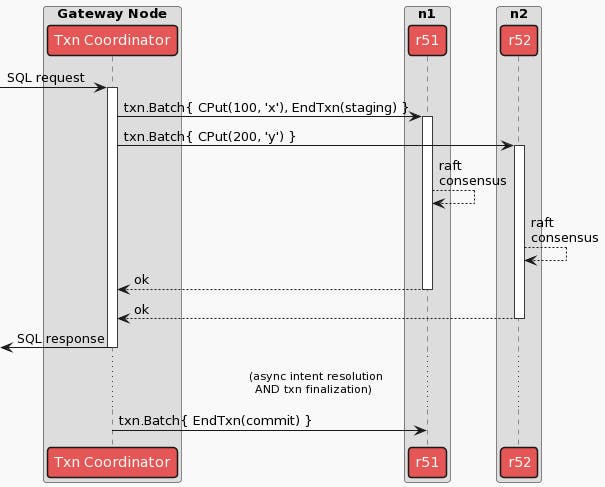
In order to ensure that all transaction records are eventually marked as explicitly COMMITTED, a “Transaction Status Recovery Procedure” had to be introduced; the TLA+ Specification (mentioned previously) formally verifies that all implicitly committed transactions will eventually become explicitly committed, and is explained further in the Parallel Commits blog post. The Recovery Procedure ensures that a transaction coordinator that dies before finishing the asynchronous follow-up work can still result in an explicitly COMMITTED record by allowing any other transaction that performs reads or writes on these keys (and thus encounters the transaction record) to kick off recovery. Once the Recovery Procedure has been initiated, the database can ensure that the keys noted in the transaction record were either correctly and durably written, in which case the transaction can be marked COMMITTED, or they were not, in which case the transaction must be marked ABORTED. This is an all-or-none proposition, of course, in order to ensure transaction atomicity.
Unexpected Commits
How does this lead to a bug in which the transaction coordinator doesn’t realize its transaction was already committed, you might ask? Well, recall that we mentioned RPC failures earlier. In the case that one of the RPCs for performing one of a transaction’s writes fail, the transaction coordinator literally does not know if that write is durable or not. It is possible that the remote side of the RPC performed correctly, durably wrote the new value to disk, and the node simply lost power or network connection before returning its gRPC codes.OK response. In the terminology of the 2PC protocol, the write has not been acknowledged. So the transaction coordinator must re-attempt the write, sending a new RPC - if the value is already durably written, we simply validate it, this is called an idempotent replay. If the value was not durably written, the write is re-attempted. In KV operations, this looks like the following:
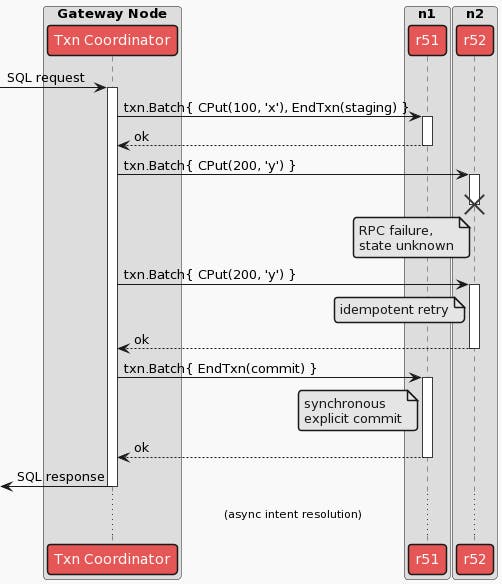
As mentioned above, however, once a transaction’s writes are durably written and the record is marked as STAGING, it is considered implicitly committed by other transactions. This means that it is possible for the RPC failure of a transaction’s writes to cause the transaction coordinator to be out of sync with the correct state of the transaction, as it is viewed by other transactions operating in the database. Additionally, once a transaction is implicitly committed, it may be eligible for the Transaction Status Recovery Procedure, initiated by other operations in the database. Hence, not only can the transaction coordinator have an ambiguous state, but it is possible for another operation to correctly interpret the “implicitly committed” state of the transaction, and mark it explicitly committed before the transaction coordinator can verify the writes and attempt to finalize the transaction itself - essentially losing a race and ending up finding that the transaction was unexpectedly committed!
Fixing Idempotency
Once a transaction is committed - either explicitly or implicitly - any changes to that transaction would be illegal, causing breaks to the rules of transaction atomicity and isolation. This makes sense - once some other operation performs a read at timestamp ts=6 and sees the following query results:
> SELECT account_id, value FROM accounts;
account_id | value
------------+-------
100 | x
200 | y
(2 rows)
With account_id=100 having value=‘x’ as written by TxnID=1, it should be illegal for TxnID=1 to later perform additional operations like writing value=’z’. Similarly, it would also be illegal for TxnID=1 to later rewrite the transaction’s timestamp to ts=10, as it would also retroactively change the query at ts=6 to have the following results:
> SELECT account_id, value FROM accounts;
account_id | value
------------+-------
(0 rows)
These behaviors are not allowed in CockroachDB, as they could cause significant bugs in client applications if our guarantees around transaction isolation were not respected. This is what the transaction coordinator is asserting when it validates its expected transaction status, and why the transaction coordinator would crash if it found itself in an unexpected state.
It turns out that the tricky part is the definition around the idempotent replay that happens when the transaction coordinator retries a failed write RPC. Generally, the idempotent replay is just validating that if we wrote value=’x’ for account_id=100, we are still writing the same value, regardless of the timestamp, since the transaction isn’t yet committed. In most cases, the timestamp of a transaction’s writes are fungible prior to the transaction being committed - the timestamp can be incremented, provided any prior read operations in the transaction could be validated via an operation known as a Read Refresh. However, once it is possible for a transaction to be considered committed, its writes become visible to other readers - and thus, changing the timestamp of a write is actually breaking idempotency by having a side effect.
How can we fix this?
If the transaction coordinator is in an ambiguous state due to RPC failures, we can essentially incorporate that into our evaluation of the idempotent replay. If we are attempting to change the timestamp of a transaction for some reason (such as the start of a new range leaseholder), and the transaction coordinator isn’t sure if the transaction could be considered committed by other readers, rather than attempting to break our guarantees or panic, we should instead acknowledge that ambiguity and instead return SQL error 40003 statement_completion_unknown. This allows the client to determine how to proceed in the face of RPC failures - the transaction can be verified externally, and potentially reattempted if it did not complete successfully. In terms of KV operations, this looks like the following: