
The Replication dashboard in the DB Console lets you monitor the replication metrics for your cluster.
To view this dashboard, access the DB Console, click Metrics in the left-hand navigation, and select Dashboard > Replication.
Review of CockroachDB terminology
- Range: CockroachDB stores all user data and almost all system data in a giant sorted map of key-value pairs. This keyspace is divided into "ranges", contiguous chunks of the keyspace, so that every key can always be found in a single range.
- Range Replica: CockroachDB replicates each range (3 times by default) and stores each replica on a different node.
- Range Lease: For each range, one of the replicas holds the "range lease". This replica, referred to as the "leaseholder", is the one that receives and coordinates all read and write requests for the range.
- Under-replicated Ranges: When a cluster is first initialized, the few default starting ranges have a single replica. As more nodes become available, the cluster replicates these ranges to other nodes until the number of replicas for each range reaches the desired replication factor (3 by default). If a range has fewer replicas than the replication factor, the range is said to be "under-replicated". Non-voting replicas, if configured, are not counted when calculating replication status.
- Unavailable Ranges: If a majority of a range's replicas are on nodes that are unavailable, then the entire range is unavailable and will be unable to process queries.
For more details, see Scalable SQL Made Easy: How CockroachDB Automates Operations.
Dashboard navigation
Use the Graph menu to display metrics for your entire cluster or for a specific node:
- When set to Graph: Cluster, data is aggregated together for all nodes in your cluster.
- When set to Graph: {node}, only data for the specific selected node is shown.
To the right of the Graph and Dashboard menus, a time interval selector allows you to filter the view for a predefined or custom time interval. Use the navigation buttons to move to the previous, next, or current time interval. When you select a time interval, the same interval is selected in the SQL Activity pages. However, if you select 10 or 30 minutes, the interval defaults to 1 hour in SQL Activity pages.
When viewing graphs, a tooltip will appear at your mouse cursor providing further insight into the data under the mouse cursor. Click anywhere within the graph to pin the tooltip in place, decoupling the tooltip from your mouse movements. Click anywhere within the graph to cause the tooltip to follow your mouse once more.
The Replication dashboard displays the following time series graphs:
Ranges
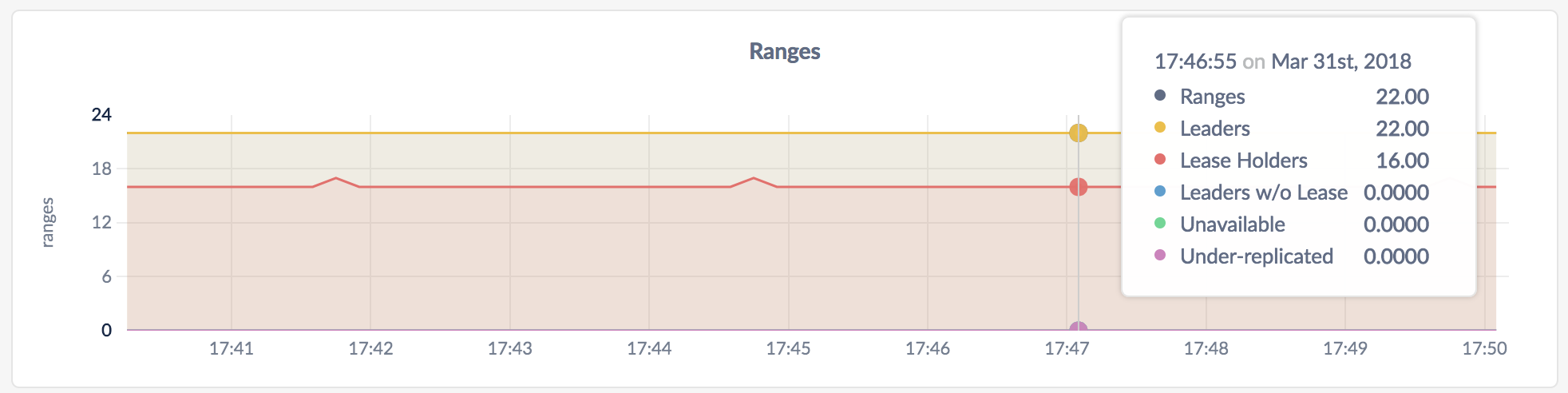
The Ranges graph shows you various details about the status of ranges.
In the node view, the graph shows details about ranges on the node.
In the cluster view, the graph shows details about ranges across all nodes in the cluster.
On hovering over the graph, the values for the following metrics are displayed:
| Metric | Description |
|---|---|
| Ranges | The number of ranges. |
| Leaders | The number of ranges with leaders. If the number does not match the number of ranges for a long time, troubleshoot your cluster. |
| Lease Holders | The number of ranges that have leases. |
| Leaders w/o Leases | The number of Raft leaders without leases. If the number if non-zero for a long time, troubleshoot your cluster. |
| Unavailable | The number of unavailable ranges. If the number if non-zero for a long time, troubleshoot your cluster. |
| Under-replicated | The number of under-replicated ranges. Non-voting replicas are not included in this value. |
Logical Bytes per Store
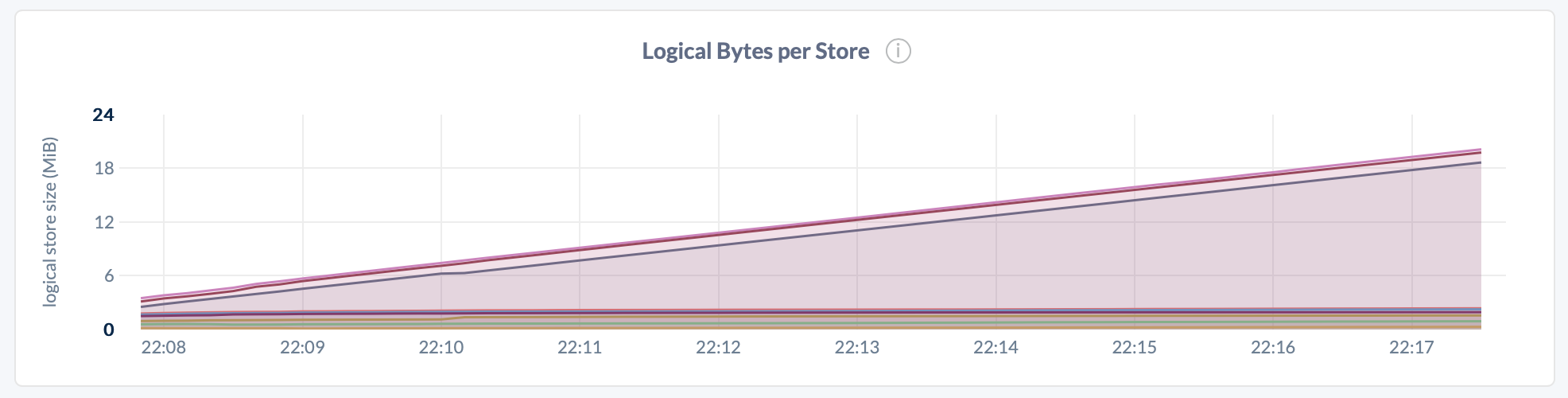
| Metric | Description |
|---|---|
| Logical Bytes per Store | Number of logical bytes stored in key-value pairs on each node. This includes historical and deleted data. |
Logical bytes reflect the approximate number of bytes stored in the database. This value may deviate from the number of physical bytes on disk, due to factors such as compression and write amplification.
Replicas Per Store
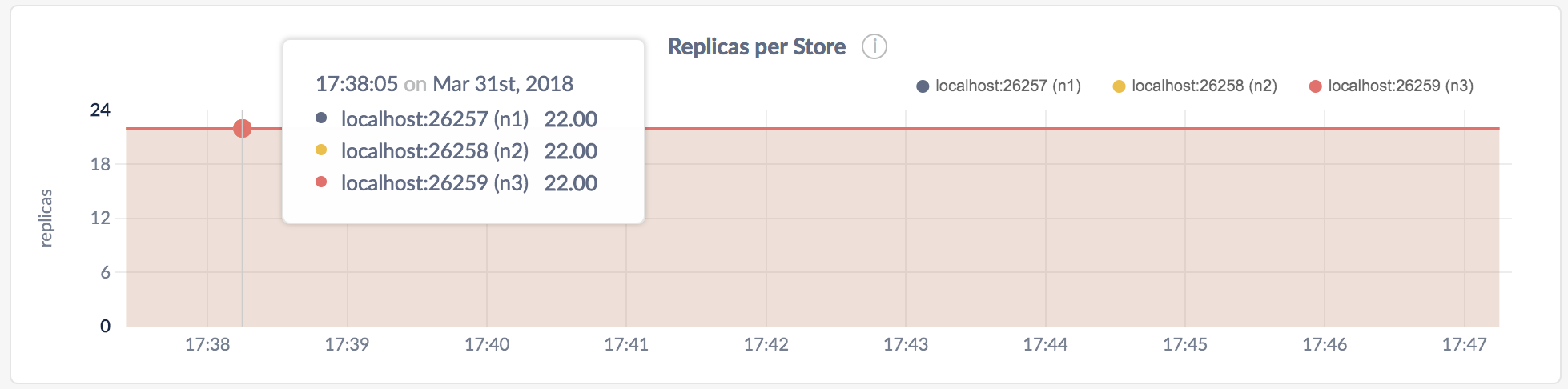
In the node view, the graph shows the number of range replicas on the store.
In the cluster view, the graph shows the number of range replicas on each store.
You can Configure replication zones to set the number and location of replicas. You can monitor the configuration changes using the DB Console, as described in Fault tolerance and recovery.
Replica Quiescence
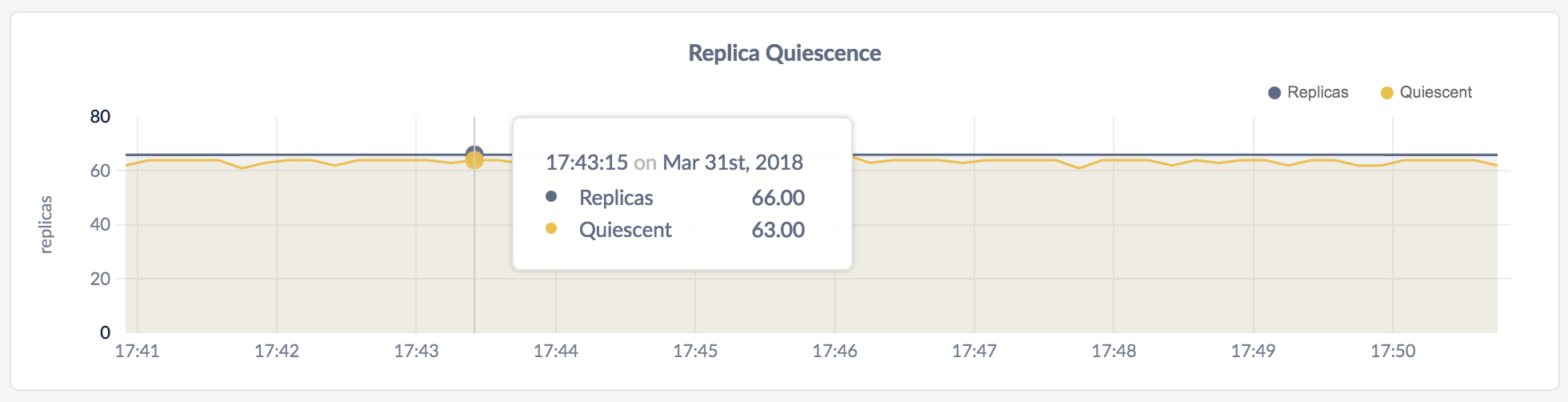
In the node view, the graph shows the number of replicas on the node.
In the cluster view, the graph shows the number of replicas across all nodes.
On hovering over the graph, the values for the following metrics are displayed:
| Metric | Description |
|---|---|
| Replicas | The number of replicas. |
| Quiescent | The number of replicas that haven't been accessed for a while. |
Snapshots
Usually the nodes in a Raft group stay synchronized by following along with the log message by message. However, if a node is far enough behind the log (e.g., if it was offline or is a new node getting up to speed), rather than send all the individual messages that changed the range, the cluster can send it a snapshot of the range and it can start following along from there. Commonly this is done preemptively, when the cluster can predict that a node will need to catch up, but occasionally the Raft protocol itself will request the snapshot.
| Metric | Description |
|---|---|
| Generated | The number of snapshots created per second. |
| Applied (Raft-initiated) | The number of snapshots applied to nodes per second that were initiated within Raft. |
| Applied (Learner) | The number of snapshots applied to nodes per second that were anticipated ahead of time (e.g., because a node was about to be added to a Raft group). This metric replaces the Applied (Preemptive) metric in 19.2 and onwards. |
| Applied (Preemptive) | The number of snapshots applied to nodes per second that were anticipated ahead of time (e.g., because a node was about to be added to a Raft group). This metric was used in pre-v19.2 releases and will be removed in future releases. |
| Reserved | The number of slots reserved per second for incoming snapshots that will be sent to a node. |
Snapshots Data Received
The Snapshots Data Received graph shows the rate of data received in bytes by each node via Raft snapshot transfers.
On hovering over the graph, the value for the following metric is displayed:
| Metric | Description |
|---|---|
{node} |
The rate of snapshot data received in bytes per node. |
Circuit Breaker Tripped Replicas
When individual ranges become temporarily unavailable, requests to those ranges are refused by a per-replica circuit breaker instead of hanging indefinitely.
In the node view, the graph shows the number of replicas for which the per-replica circuit breaker is currently tripped, for the selected node.
In the cluster view, the graph shows the number of replicas for which the per-replica circuit breaker is currently tripped, for each node in the cluster.
On hovering over the graph, the value for the following metric is displayed:
| Metric | Description |
|---|---|
{node} |
The number of replicas on that node for which the per-replica circuit breaker is currently tripped. |
Circuit Breaker Tripped Events
When individual ranges become temporarily unavailable, requests to those ranges are refused by a per-replica circuit breaker instead of hanging indefinitely. While a range's per-replica circuit breaker remains tripped, each incoming request to that range triggers a ReplicaUnavailableError event until the range becomes available again.
In the node view, the graph shows the total number of
ReplicaUnavailableErrorevents logged since thecockroachprocess started, for the selected node.In the cluster view, the graph shows the total number of
ReplicaUnavailableErrorevents logged since thecockroachprocess started, for each node in the cluster.
| Metric | Description |
|---|---|
{node} |
The number of ReplicaUnavailableError events on that node since the cockroach process started. |
Other graphs
The Replication dashboard shows other time series graphs that are important for CockroachDB developers:
- Leaseholders per Store
- Average Queries per Store
- Range Operations
For monitoring CockroachDB, it is sufficient to use the Ranges, Replicas per Store, and Replica Quiescence graphs.
Summary and events
Summary panel
A Summary panel of key metrics is displayed to the right of the timeseries graphs.
| Metric | Description |
|---|---|
| Total Nodes | The total number of nodes in the cluster. Decommissioned nodes are not included in this count. |
| Capacity Used | The storage capacity used as a percentage of usable capacity allocated across all nodes. |
| Unavailable Ranges | The number of unavailable ranges in the cluster. A non-zero number indicates an unstable cluster. |
| Queries per second | The total number of SELECT, UPDATE, INSERT, and DELETE queries executed per second across the cluster. |
| P99 Latency | The 99th percentile of service latency. |
If you are testing your deployment locally with multiple CockroachDB nodes running on a single machine (this is not recommended in production), you must explicitly set the store size per node in order to display the correct capacity. Otherwise, the machine's actual disk capacity will be counted as a separate store for each node, thus inflating the computed capacity.
Events panel
Underneath the Summary panel, the Events panel lists the 5 most recent events logged for all nodes across the cluster. To list all events, click View all events.
The following types of events are listed:
- Database created
- Database dropped
- Table created
- Table dropped
- Table altered
- Index created
- Index dropped
- View created
- View dropped
- Schema change reversed
- Schema change finished
- Node joined
- Node decommissioned
- Node restarted
- Cluster setting changed
