November 25, 2020. If you work in tech infrastructure, that’s a date you probably remember. On that day, AWS’s US-east-1 experienced a significant outage, and it broke a pretty significant percentage of the internet.
Adobe, League of Legends, Roku, Sirius XM, Amazon, Flickr, Giphy, and many, many more experienced issues or went offline completely as a result of the outage.
That kind of outage costs time and money. It also does something that’s arguably even more expensive in the long run: it erodes customer confidence in your product.
Outages like that are one of the reasons why fault tolerance is an integral part of most modern application architectures.
What is fault tolerance?
Fault tolerance describes a system’s ability to handle errors and outages without any loss of functionality.
For example, here’s a simple demonstration of comparative fault tolerance in the database layer. In the diagram below, Application 1 is connected to a single database instance. Application 2 is connected to two database instances — the primary database and a standby replica.

In this scenario, Application 2 is more fault tolerant. If its primary database goes offline, it can switch over to the standby replica and continue operating as usual.
Application 1 is not fault tolerant. If its database goes offline, all application features that require access to the database will cease to function.
Of course, this is just a simple example. In reality, fault tolerance must be considered in every layer of a system (not just the database), and there are degrees of fault tolerance. While Application 2 is more fault tolerant than Application 1, it’s still less fault tolerant than many modern applications. (See examples of fault-tolerant application architecture.)
Fault tolerance can also be achieved in a variety of ways. These are some of the most common approaches to achieving fault tolerance:
Multiple hardware systems capable of doing the same work. For example, Application 2 in our diagram above could have its two databases located on two different physical servers, potentially in different locations. That way, if the primary database server experiences an error, a hardware failure, or a power outage, the other server might not be affected.
Multiple instances of software capable of doing the same work. For example, many modern applications make use of containerization platforms such as Kubernetes so that they can run multiple instances of software services. One reason for this is so that if one instance encounters an error or goes offline, traffic can be routed to other instances to maintain application functionality.
Backup sources of power, such as generators, are often used in on-premises systems to protect the application from being knocked offline if power to the servers is impacted by, for example, the weather. That type of outage is more common than you might expect.
Fault tolerance vs. high availability
High availability refers to a system’s total uptime, and achieving high availability is one of the primary reasons architects look to build fault-tolerant systems.
Technically, fault tolerance and high availability are not exactly the same thing. Keeping an application highly available is not simply a matter of making it fault tolerant. A highly fault-tolerant application could still fail to achieve high availability if, for example, it has to be taken offline regularly to upgrade software components, change the database schema, etc.
In practice, however, the two are often closely connected, and it’s difficult to achieve high availability without robust, fault-tolerant systems.
Fault tolerance goals
Building fault-tolerant systems is more complex and generally also more expensive. If we think back to our simple example from earlier, Application 2 is more fault tolerant, but it also has to pay for and maintain an additional database server. Thus, it’s important to assess the level of fault tolerance your application requires and build your system accordingly.
Normal functioning vs. graceful degradation
When designing fault-tolerant systems, you may want the application to remain online and fully functional at all times. In this case, your goal is normal functioning — you want your application, and by extension the user’s experience, to remain unchanged even if an element of your system fails or is knocked offline.
Another approach is aiming for what’s called graceful degradation, where outages and errors are allowed to impact functionality and degrade the user experience, but not knock the application out entirely. For example, if a software instance encounters an error during a period of heavy traffic, the application experience may slow for other users, and certain features might become unavailable.
Building for normal functioning obviously provides for a superior user experience, but it’s also generally more expensive. The goals for a specific application, then, might depend on what it’s used for. Mission-critical applications and systems will likely need to maintain normal functioning in all but the most dire of disasters, whereas it might make economic sense to allow less essential systems to degrade gracefully.
Setting survival goals
Achieving 100% fault tolerance isn’t really possible, so the question architects generally have to answer when designing fault-tolerant systems is how much they want to be able to survive.
Survival goals can vary, but here are some common ones for applications that run on one or more of the public clouds, in ascending order of resilience:
- Survive node failure. Running instances of your software on multiple nodes (often different physical servers) with the same AZ (data center) can allow your application to survive faults (such as hardware failures or errors) on one or more of those nodes.
- Survive AZ failure. Running instances of your software across multiple availability zones (data centers) within a cloud region will allow you to survive AZ outages, such as a specific data center losing power during a storm.
- Survive region failure. Running instances of your software across multiple cloud regions can allow you to survive an outage affecting an entire region, such as the AWS US-east-1 outage mentioned at the beginning of this post.
- Survive cloud provider failure. Running instances of your software both in the cloud and on-premises, or across multiple cloud providers, can allow you to survive even a full cloud provider outage.
These are not the only possible survival goals, of course, and fault tolerance is only one aspect of surviving outages and other disasters. Architects also need to consider factors such as RTO and RPO to minimize the negative impact when outages do occur. But considering your goals for fault tolerance is also important, as they will affect both the architecture of your application and its costs.
The cost of fault tolerance
When architecting fault-tolerant systems, another important consideration is cost. This is a difficult and very case-specific factor, but it’s important to remember that while there are costs inherent with choosing and using more fault-tolerant architectures and tools, there are also significant costs associated with not choosing a high level of fault tolerance.
For example, operating multiple instances of your database across multiple cloud regions is likely to cost more on the balance sheet than operating a single instance in a single region. However, there are a few things you must also consider:
- What does an outage cost in dollars? For mission-critical systems, even a few minutes of downtime can lead to millions in lost revenue.
- What does an outage cost in reputation damage? Consumers are demanding, particularly in certain business verticals. An application outage of just a few minutes, for example, could be enough to scare millions of customers away from a bank.
- What does an outage cost in engineering hours? Any time your team spends recovering from an outage is time they’re not spending building new features or doing other important work.
- What does an outage cost in team morale and retention / hiring? Outages also often come at inconvenient times. The US-east-1 outage, for example, came the day before Thanksgiving, when most US-based engineers were on vacation, forcing them to rush into the office on a holiday or in the middle of the night to deal with an emergency. Great engineers generally have a lot of choices when it comes to where they work, and will avoid working anywhere where those sorts of emergencies are likely to disrupt their lives.
These are just a few of the costs associated with not achieving a high level of fault tolerance.
The way you achieve fault tolerance can also have a significant impact on your costs. Here, let’s consider the real-world case of a major electronics company that needed to build a more scalable, fault-tolerant version of its existing MySQL database.
The company could have made that MySQL database more fault tolerant by manually sharding it, but that approach is technically complex and requires a lot of work to execute and maintain. Instead, the company chose to migrate to CockroachDB dedicated, a managed database-as-a-service that is inherently distributed and fault tolerant.
Although CockroachDB dedicated itself is more expensive than MySQL (which is free), migrating to CockroachDB enabled the company to save millions in labor costs because it automates the labor-intensive manual sharding process and resolves many of the technical complexities that manually sharding would introduce.
Ultimately, the company achieved a database that is as or more fault tolerant than manually sharded MySQL while spending millions of dollars less than what manually sharded MySQL would ultimately have cost them.
This’s not to say that CockroachDB or any specific tool or platform will be the most affordable option for all use cases. However, it’s important to recognize that the methods you choose for achieving your fault tolerance goals can have a significant impact on your costs in both the short and long term.
What does manually sharding legacy RDBMS really cost?
Fault-tolerant architecture examples
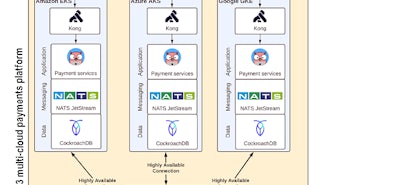
There are many ways to achieve fault tolerance, but let’s take a look at a very common approach for modern applications: adopting a cloud-based, multi-region architecture built around containerization services such as Kubernetes.

An example of a fault-tolerant multi-region architecture. Click to enlarge.
This application could survive a node, AZ, or even region failure affecting its application layer, its database layer, or both. Let’s take a closer look at how that’s possible.
Achieving fault tolerance in the application layer
In the diagram above, the application is spread across multiple regions, with each region having its own Kubernetes cluster.
Within each region, the application is built with microservices that execute specific tasks, and these microservices are typically operated inside Kubernetes pods. This allows for much greater fault tolerance, since a new pod with a new instance can be started up whenever an existing pod encounters an error. This approach also makes the application easier to scale horizontally — as the load on a specific service increases, additional instances of that service can be added in real time to handle the load, and then removed when the load dies down again and they’re no longer needed.
Message queuing and solving the dual-write problem in microservice architectures.
Achieving fault tolerance in the persistence (database) layer
The application in the diagram above takes a similar approach in the database layer. Here, CockroachDB is chosen because its distributed, node-based nature naturally provides a high level of fault tolerance and the same flexibility when it comes to scaling up and down horizontally. Being a distributed SQL database, it also allows for strong consistency guarantees, which is important for most transactional workloads.
CockroachDB also makes sense for this architecture because although it’s a distributed database, it can be treated like a single-instance Postgres database by the application — almost all the complexity of distributing the data to meet your application’s availability and survival goals happens under the hood.