Before the dominance of the cloud, calculating the cost of a database was a pretty simple equation: software costs + hardware costs = database costs. If you chose an open source product, the software cost might melt away. While the cloud has fundamentally changed how we consume and deploy software, too many people are still using this outdated calculation.
The truth is, there are a lot more things to consider when pricing out the total cost of a database. The hardware and software costs are still there, but you also need to think about the price of scaling the database, of integrating with your existing and future systems, and of planned–or unplanned–downtime.
When pricing out the cost of a cloud database, it’s crucial to ask these questions upfront. In a an old episode of The Cockroach Hour, we presented a complete rubric of all the questions to ask when calculating the true cost of a database. Costs fall into three main categories: hard costs, operational costs, and soft costs.
If you want to see a fully fleshed out report that captures all the soft and hard costs check out this ~50 page Do more with less report. Seven different companies were evaluated in that report and the insights gleaned will help you reduce costs, improve uptime, and increase the pace of innovation.
In this recap of our original database costs webinar, we walk through the line items in the rubric, and follow-up with an in-depth template you can use in your own calculations.
Hard database costs
On the surface, this portion of the equation hasn’t changed much since the pre-cloud days. The hard costs for a database fall into two categories: the software license and the hardware. However, the cloud introduces a few new questions to ask of your hardware and software costs.
Cloud database software costs
There are lots of software licenses on the market, which can be grouped into three categories:
- Traditional Enterprise: This has been a model for thirty-odd years in enterprise software, before the cloud. You pay a large upfront fee for the enterprise software license (usually in the hundreds of thousands of dollars, plus a support and maintenance fee). After that purchase, you pay additional costs for added functionality and upgrades.
- Full Open Source: A fully free, Apache license. The costs associated with a free software license aren’t non-existent, though. You need to pay to maintain it, support it, and de-risk it. We’ll go into these costs in a bit.
- Commercial Open Source: This model came about 10-15 years ago as a viable solution to solve some of the issues companies saw with full open source licenses, like indemnification and support.
Cloud database hardware costs
Hardware costs look different today than they did 30 years ago. But those hardware costs haven’t gone away just because there’s not a giant box humming in the server room. Sure, there are differences: you might negotiate price with a vendor, or take advantage of the economies of scale (don’t mean to disparage this), but it’s a cost you need to consider.
You also still need to manage and operate all these. The operational costs don’t just melt away. There is considerable time spent in the interfaces of these cloud providers to actually manage these things and understanding from an operations point of view, so ease of use is important.
Operational database costs
On top of hardware and software costs, there are day-to-day costs incurred by running the database. These vary a lot based on the vendor you choose (and their pricing structure), but stem from the same question: what happens when we want to do X task in the future?
Over the course of using a database, you’re going to have to deal with disaster recovery, with scale, with integrating the system with other tools. It’s very easy to think “We’ll cross that bridge when we get to it.” But when calculating the true cost of a database, you need to think about these inevitabilities and price out what it will cost when you need to cross these bridges.
Disaster recovery: What’s the cost of database failure?
No matter how many layers of abstraction you place over your hardware, at the end of the day, we’re dealing with mechanical devices. And those devices will fail. The cost of a temporary or catastrophic challenge needs to be considered when choosing your database to deploy your application. While there are many reasons an application might fail, the database is the primary cause of many outages. Old versions, write bottlenecks, memory issues, locked transactions, misconfigurations, hardware failure. You need to prepare for these inevitabilities, because they will happen at some point.
Both planned and unplanned downtime can result in significant cost and while this spend may not be easily calculated, it should still be considered as part of your database choice. Each business is different and the impact of downtime is different for each, but these are a few items to consider when calculating the cost of downtime for your business:
- Loss of revenue: Missed opportunity to conduct online commerce or engage a prospect
- Reputation impact: Consumers may just go on to the next offer, your competitor
- Client satisfaction: Loss of trust in your product or service due to observed issue
- Regulatory costs: Jurisdictional regulations sometimes fine organizations for data issues
- Legal liability: In extreme cases, lawsuits may be filed associated with data loss
There are some pretty simple and more straightforward technical reasons why data loss and downtime can be an issue. Often we find ourselves dealing with an extended RPO/RTO period and will endure the high technical costs.
Scale: What’s the cost of sharding?
For most cloud databases, scale is accomplished by increasing the size of the instance. However, with this approach, you’re limited with the max size available to you. What happens when you want to scale beyond this, or need global scale?
Some databases, like AWS Aurora, allow you to expand beyond a single instance (RDS) and allow for multiple instances. However, this is for reads only and limits the amount of transaction volume you can handle as there is no capability to scale write nodes. You still face the size limit. Further, this single write node configuration limits your availability to scale access across broad geographies as you will always encounter physical latencies for write access.
If you choose to scale an open-source database like PostgreSQL or MySQL, you will eventually need to shard the database. There are massive costs associated with this approach. For one, you will need to modify your application, which introduces risk. You will also need to configure a new instance and cut over to this new configuration at some point, typically in the middle of the night. You will have extra costs associated with the hardware and the pain it causes for the team… and this is all the best case scenario. If something goes wrong in this process, you wind up with unplanned downtime. Also, management costs of a sharded database increase exponentially with each new shard.
Integration: What’s the cost of using other tools?
Your database does not exist in a vacuum. It’s going to be integrated into other parts of your IT platform. You aren’t going to run OLAP in an OLTP database. There’s a reason why data warehouses came about. And so integration between your database and other tools, like a data warehouse, is important. And depending on your database, it can be costly. Do your use cases require Kafka or some sort of stream processing? Are you using a data lake?
Evaluate hidden database costs before buying
Beyond operational costs, there are even harder-to-quantify questions to ask that constitute the hidden cost of a cloud database. These include the compliance costs, the competitive risk, potential for vendor lock-in, and your ability to attract talent. The best way to factor in all the hidden costs of deploying, managing, and scaling a traditional relational database is to do your evaluation using this report.
Further reading on cost-efficient architecture
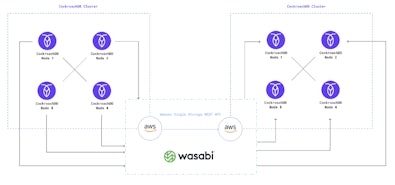
• How to make backups faster and more cost-effective with Wasabi
• How to increase engineering output while reducing cost
• A sports betting app saved millions switching from PostgreSQL to CockroachDB
• An electronics giant saved millions after migrating from MySQL to CockroachDB