Until recently, CockroachDB’s SQL was suffering from a serious, long-standing bug – a schrödinbug, in fact – in its handling of table and column references. This blog post outlines how fuzz testing uncovered the error, how we discovered that our way of using Go was partly to blame, and how we addressed the issue using a form of strong typing.
tl;dr:
- Fuzz testing is good.
- Don’t use the same type for different things. It crashes rockets and CockroachDB, too.
Tale of a Schrödinbug
Schrödinbug_: a bug that manifests only after someone reading source code or using the program in an unusual way notices that it never should have worked in the first place, at which point the program promptly stops working for everybody until fixed._
Like in many programming languages, SQL execution is separated in phases: first the text of the query is lexed and parsed; then the parsed syntax tree is analyzed for semantic correctness; then the checked tree is transformed into a query plan for execution. Until a few weeks ago, the team at CockroachDB was only looking at “deep” issues in the SQL code related to how queries were executed, optimized etc.: We assumed that parsing and semantic analysis were done deals.
That is, until Matt decided it was a good idea to throw a random SQL syntax generator at our engine to check the coverage of our existing tests. This is part of our ongoing effort to test SQL coverage as a part of readying CockroachDB for the 1.0 release.
The way his generator works is that the generator looks at the same SQL grammar as used by CockroachDB’s parser, and generates random strings that are also accepted by the grammar. This is actually a form of fuzz testing, a strategy that has recently become popular as an extremely powerful tool for detecting long-standing but obscure bugs in code that handles external input.
The tests were meant to exercise the error checking code in CockroachDB. Many resulting strings were purposefully semantically erroneous (e.g. SELECT 2 / 0, SELECT non_existent_column FROM non_existent_table). The expected outcome was that each query would:
- Be accepted by the parser.
- Either run successfully, or report an error to the client from a semantic check in CockroachDB’s SQL code.
Instead of the expected client errors, this generator promptly detected cases where the entire database server running the query would fail dramatically, with a non-recoverable panic. There were even multiple errors in different places, so we knew we were facing either multiple bugs or a more fundamental issue with a larger scope.
The queries causing these errors were conspicuously out of this world, for example:
SELECT TREAT . * [ PLACEHOLDER IS UNKNOWN ] FROM d.t;
SELECT t.* IS NOT TRUE
SELECT TRIM ( TRAILING LOW . * [ ROW ( ) ] );
And thus the first task was to narrow down the root cause(s). After a short investigation, we discovered this was a fundamental issue, and as soon as we had understood this it was easy to imagine many other rather straightforward queries that would fail the entire server too:
SELECT COUNT(nonexistent_column.*) FROM table;
SELECT some_column.*[10] FROM table;
INSERT INTO table(col.*) VALUES (1)
We even found queries that should cause an error didn’t and would run with unpredictable results:
INSERT INTO table VALUES(1) RETURNING x[1]
INSERT INTO table VALUES(1) ON CONFLICT DO UPDATE SET x.* = 10
In other words, as soon as we knew the bug was there, we could see it all over the place.
We made a mistake and perhaps Go did, too
The cause of the problem was a combination of a design flaw in a critical part of CockroachDB and an inconvenience caused by Go.
A flaw in CockroachDB hidden in plain sight
There are at least five very different things that can be named in SQL: a table, a function, a column group, a single column, and, if the database supports composite types, a part of a larger object.
However, “for simplicity,” it was decided early on that CockroachDB would use a single Go data type for all these things, the `QualifiedName`. This type was a bit complicated. It was a struct with two states, “just parsed” and “normalized.” The data stored in the struct was to be interpreted very differently depending on the state. The parser would populate the struct with raw name parts found using the grammar, and depending where the `QualifiedName` was placed in the syntax tree, it was to be normalized in different ways by the semantic checker handling the syntax tree.
Here the first flaw can be found. Although there are five categories of objects that can be named in SQL, CockroachDB only internally used only two normalization algorithms: table name or column name. Column groups (those written with `tablename.*`) were not handled directly during normalization but rather at each point where a column group was to be accepted or rejected.
Of course (hindsight = 20/20). We had made mistakes and there were several places where the check for column groups was not implemented correctly. Moreover, we didn’t check that function names had the proper structure. We had simply forgotten, and we didn’t catch this in tests earlier because, after all, who would in their right mind write function calls like “a.*[3](d)”?
The better design would have been to use more normalization states, one for each kind of name.
Go encourages bad practices, too
When we implemented the `QualifiedName` struct, we used the same fields to carry the data in both states (pre- and post-normalization). This is because Go supports neither unions like in C nor sum types, which is by itself a major shortcoming but not directly a problem here.
The crux instead is that the correctness of the code using `QualifiedName` was very much dependent on using its fields properly, at each point of use. This made the code using `QualifiedName` responsible for not only checking the normalization state but also testing explicitly that the data in the fields was appropriate (or not) in every context where a name was used.
In this particular case, our parser accepts names with extra subscripts (e.g. `x[1]`) because we want to support this in the future. However, they are not yet supported by CockroachDB, so for now, we need to reject them before execution. Since this syntax can be supported in different ways depending on context, we didn’t place the check in the common normalization function; instead the code using the struct was responsible for checking whether subscripts were accepted or not.
Now, realize that meanwhile, the Go language and its designers very much promote direct access to struct fields for “simple uses,” instead of suggesting to systematically encapsulate objects and use method accessors as is done in Java or C++. This is the current tune in CockroachDB’s code.
And all the “simple uses” of `QualifiedName` we had written throughout CockroachDB’s source code were actually all missing a check that subscript notation wasn’t used. What we really needed was an accessor method with a common check and we hadn’t so realized; in other words, this problem was almost bound to happen ever since we followed Go’s suggestion to avoid encapsulation by default.
Strong typing to the rescue
Trying to address the issue by manually adding the missing checks at every use of `QualifiedName` was risky (there were many; how could we be sure to not miss any?) and foremost too brittle: What about the next person adding a new use of `QualifiedName` somewhere?
Instead we went for what all good programming textbooks and best practices had told us to do from the beginning: use different types for different things!
The full solution is outside of the scope of this blog post and can be explored here.
In summary, we now have one type called `UnresolvedName` produced by the parser; then, during semantic analysis, objects of this type are normalized into objects of different types, either `TableName`, `FunctionName`, `AllColumnsSelector` / `UnqualifiedStar` (for column groups) or `ColumnItem` (for individual columns or sub-fields/subscripts). Since each type now has its own field and interface, it becomes more difficult to use a name improperly after it was normalized. As a result, the previous type `QualifiedName` could be removed entirely.
Implementing this fix involved changes to pretty much the entire SQL code base. The review of this patch was grueling due to the large number of changes. However each part of the change was localized and thus checking its correctness was still tractable. In the process we fixed all the corresponding bugs found by our random generator, as well as a couple of other bugs that only became obvious during the change, for example latent errors with:
CREATE TABLE newtable (x INT, CHECK (COUNT(*) = 1))
CREATE TABLE db1.t (x INT, FOREIGN KEY (x) REFERENCES db2.t(x))
(The last two statements would only cause the server to fail at the first INSERT on the new table).
Lesson learned
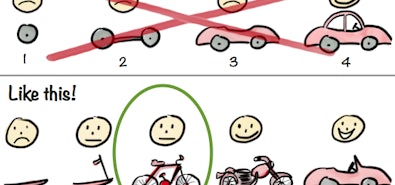
Imagine you have a toy, and the object of the toy is to fill it by passing its contents through appropriate slots. Ideally, you’d want the toy to tell you that you’re doing it wrong by using different shapes for the different objects and holes. Instead, with CockroachDB, all the objects and holes were shaped the same and the rule was instead to “pay attention to the color.” What’s worse is that Go didn’t help us realize we were also color blind. 
Strong(er) typing really helped us put things back in shape.
We’ll do it more from now on.