Roachfest '23
Join the most innovative minds in data architecture on October 3-4 in NYC.
Register nowAt Netflix, data movement and data processing are essential functions that present significant challenges because of the vastness of their data architecture. There are so many different data sources to keep in sync and so many different consumers of the data that need accurate (and often) real-time access. Solving these challenges requires some clever engineering gymnastics that we’ll get to below.
The content for this blog comes from a conversation between Netflix Senior Engineer, Vlad Sydorenko, and our own Director of Engineering, Jordan Lewis, in which they unpack how Netflix moves and processes data that comes from CockroachDB. (If you want to get to know Vlad a little bit you can check out this short interview.)
The insights gleaned from their event-driven system help drive important business decisions that create better user experiences and substantial value for the company. Those insights are possible because of the data mesh that connects different sources, defines a pipeline, and makes the data accessible and useful.
Why Netflix builds Data Mesh
At Netflix, there’s a buffet of different operational data stores in use. They use CockroachDB, MySQL, Postgres, Cassandra, and more. Each one is used for its particular strength.
CockroachDB, for example, is a powerful distributed-operational data store for Netflix. Because it’s touched directly by “customers” (aka Netflix engineers), it holds data that Netflix wants to garner insight from. CockroachDB can run analytical queries on the data but not to the degree that Netflix is looking for. Which means Netflix needs a way to get the operational data from CockroachDB into a data warehouse where they have iceberg tables (RedShift, Google Cloud, BigQuery…). Once the data arrives in the warehouse, there are a lot of different insights people would like to glean from it.
Enter: Data Mesh.
In our industry, “data mesh” is a known term that means something like decentralized data architecture. But at Netflix, it means something different. “Data Mesh” refers to the pipeline they use to move and process data between systems.
For example, Data Mesh allows the operational data from CockroachDB to be extracted once, and then to be processed in the same pipeline in a variety of different ways. It could arrive in an iceberg table where queries are run, like a machine learning model for checking general health. Then it could get pulled into ElasticSearch for searching on the data, and then someone might decide that they’d like this same data but slightly modified, so they want to enrich it somewhere.
Data Mesh makes all this possible at scale.
The architecture of Data Mesh at Netflix
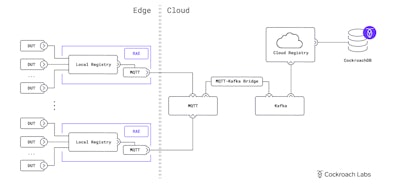
Data Mesh allows Netflix engineers to define a connector that extracts the data from a data store and puts it into a special Kafka topic. But the data needs to be translated from the data store into something that Data Mesh understands. For that, Netflix uses a CDC connector (more details on that below).
With CockroachDB, they use changefeeds and a CDC connector to translate source data into a special serialized format built on top of Apache Avro.
After the data actually makes it into the special Kafka topic (the cold source), there’s a list of sources available from which “customers” can begin building pipelines. Multiple pipelines can be built from here using the same source data. For example, each team will have a different pipeline. During the process of defining the pipeline, “customers” can add as many sources as they want. And the processors can be added to transform data or write to another data store. All the data in Data Mesh is schematized, so fields can be defined that provide general insight into what’s going on with the data.
The processing is about to speed up, so reference the diagram from Netflix below for visual support:
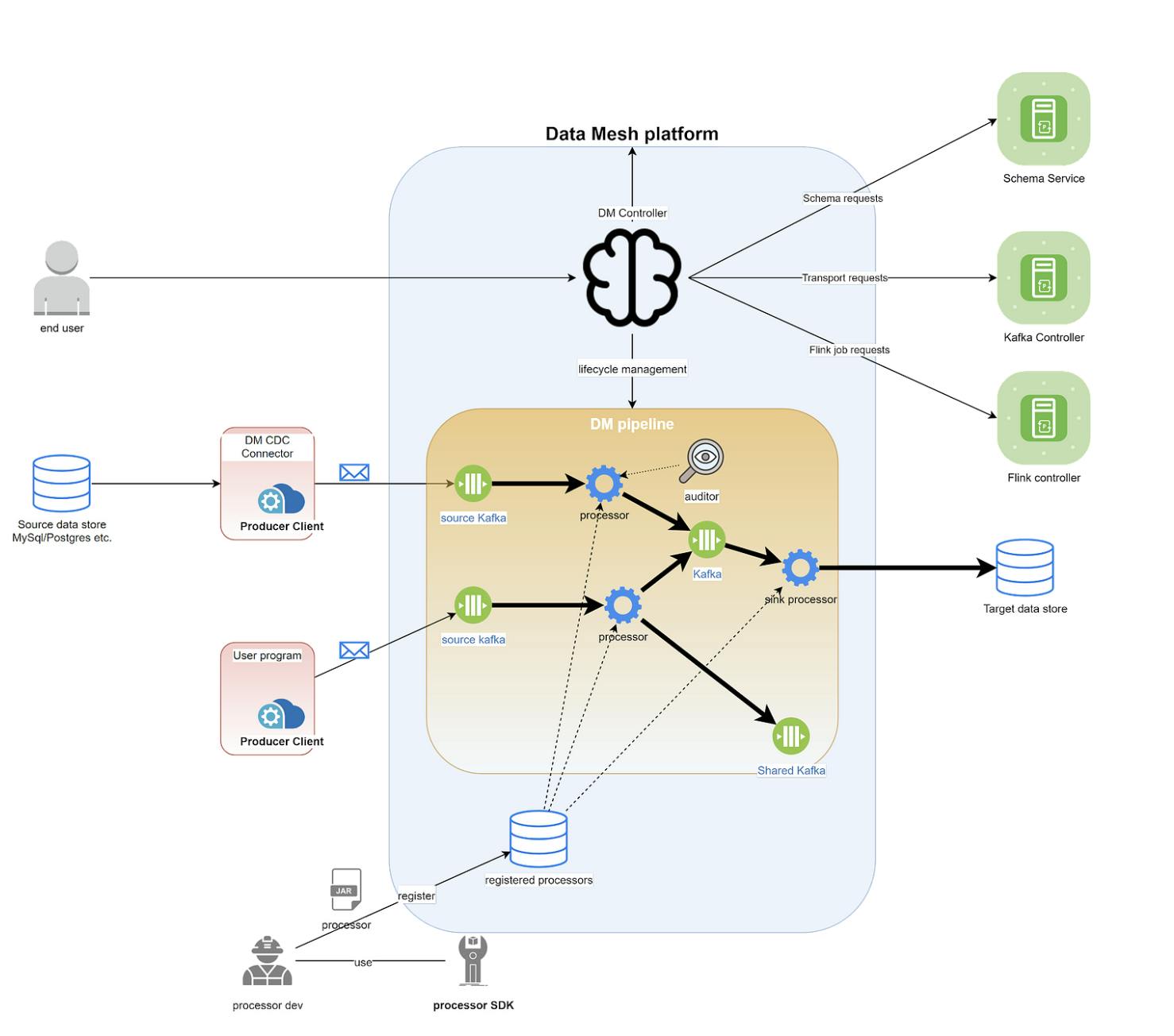
Image Credit: sourced from the Netflix blog
So first there is the source, and then the processor, and from that processor there’s the stream of data that downstream processors can consume, or streams of data can be joined and then written to the target datastore.
Often there are multiple sources of data in a single pipeline. Every source writes to the processor, which enriches the data by calling a third-party endpoint. Then all the streams are merged and written to the target data stored by a sync processor. Right now, all the processors are flink jobs. (Apache Flink is a versatile tool for stream processing.)
Example of a data pipeline with CockroachDB
At Netflix, there’s an architecture called Studio Search. This architecture helps Netflix engineers search up-to-date data products using, essentially, an index. A “data product” can be made up of different data spread out across multiple tables and multiple databases that gets woven together into something useful.
The challenge is keeping the data products fresh. Whenever an underlying table changes in some way, the entire view needs to be changed to keep the data product fresh.
In CockroachDB, for example, there could be ten tables, each with different chunks of data. Whenever something changes in one of those tables, it triggers a change data capture event. There’s a flink processor sitting around waiting for this moment. It queries all the other tables, then builds out the current state of the data product (changed and unchanged data) and sends the complete picture downstream to ElasticSearch.
This is how Netflix works with CockroachDB to constantly keep the search index fresh.
Why Netflix built a CockroachDB CDC connector
CockroachDB provides changefeeds that can be set up with a single SQL query that generates a stream of data that can be consumed and written to destinations before being sent downstream.
In an ideal world, a changefeed would get set up and the events would get sent to the Kafka topic, which is a data mesh source that could then be consumed. But that ideal world doesn’t account for the complexity of the data architecture at Netflix. They needed to build a connector for several reasons: data formats, schema change handling, backfill management, ordering, and data enrichment.
Data formats
At the time Netflix began building their CockroachDB connector, there were no CDC Queries in CockroachDB. So they needed something to translate events from one format to another. If they began building the connector today, it wouldn’t have been an issue. There is a native CDC Queries capability now in CockroachDB that can be used to:
- Filter out specific rows and columns from changefeed messages to decrease the load on your downstream sink and support outbox workloads.
- Modify data before it emits to reduce the time and operational burden of filtering or transforming data downstream.
- Stabilize or customize the schema of your changefeed messages for increased compatibility with external systems.
Schema change handling
Whenever schema changes, Netflix needs to propagate the schema change downstream through all the pipelines to all of the consumers. At every step, they check for compatibility of the change. Netflix defines compatibility in their own unique way — it’s not generic. For this reason, Netflix needed some place (the connector) to put their logic for schema change handling.
*Note: Schema changes at Netflix are unusually complex because of how large their data architecture is. The changes can’t be isolated to a single database and it’s very challenging to keep everything in sync at the same time. This level of complexity is unlikely to exist in most other businesses.
Backfill management
Netflix frequently needs ad hoc backfills. For example, when there’s a stream of data and it’s a pipeline, there are a lot of moving parts, things break, and data gets lost. When “customers” notice this, the first thing they think to do is to re-ingest everything that’s currently in the table through the pipeline to fill the gaps. This is cumbersome. But in CockroachDB, the way to create a new ad hoc backfill is to create a new changefeed with initial scan turned on. So that gets built into the connector.
Ordering requirements
Netflix has specific ordering requirements for the events and the semantics that connectors provide across different data stores, like MySQL, Postgres, Cassandra, and CockroachDB.
The tricky part is that changefeeds have looser requirements. For example, the events can be sent multiple times when a failure occurs. Netflix wants to avoid that. So they added an additional step to enforce requirements. They have a state that checks the timestamp of the event. Then they see whether or not the event has been previously processed so they only emit the events once.
Data enrichment
This data enrichment capability was also built before CockroachDB released CDC Queries, but the intention was to build an operation that could capture details about what’s happening in a row. Was it an INSERT, an UPDATE, a DELETE? Netflix also had to mark the backfill events differently, so they needed an operation that could enrich this data and send the events downstream.
Parting thoughts
If you’re interested in learning more about data movement and processing at Netflix, the best way to capture all the little nuances would be to watch this full episode with Vlad Sydorenko and Jordan Lewis:
There’s an underlying assumption being made in this conversation about the importance of event-driven systems and the insights available from real-time data. Netflix is demonstrating how to garner real-time insights from an operational data store like CockroachDB that are used to build better user experiences and a better business.