

User data. Application data. Customer history. User account data. Behavioral data. It gets called many things, but if you’re operating any kind of application at scale, metadata is probably at the very heart of your business, even if you don’t think about it that way. That’s because when you do metadata right, people won’t notice you’ve done anything at all.
Before we dive into the best practices for making sure your metadata store is so good it’s invisible, let’s take a quick look at an example that illustrates the importance of doing this right.
An example of how user metadata matters
First, consider the example of a popular online game. At a minimum, the game needs to maintain a record of items – in-game skins the player has purchased or earned, for example – associated with each player. They may also store statistical data related to the player’s performance, a list of the player’s in-game friends for easy matchmaking, and more.
Often, this aspect of a game gets less attention than other factors such as game server availability, gameplay balance, and how a game looks and feels. But any kind of issue with this metadata can ruin the player experience just as thoroughly as poor balance. If a player buys an item and then doesn’t see it in their inventory, that’s a big problem. If a player logs in but their friends list won’t load, that’s a ruined gaming session. A consistency issue in your metadata database – or even worse, an outage – can quickly become a player experience disaster.
This specific example comes from a real CockroachDB customer in the online gaming industry, but the truth is that every application stores user metadata, and it generally plays a critical role in the user experience.
So, how can we ensure that our metadata store remains available, performant, and consistent? It’s not always easy, but here are some best practices to follow, collated from our experience providing the database software that powers the user metadata stores of global enterprise customers across a wide variety of industries.
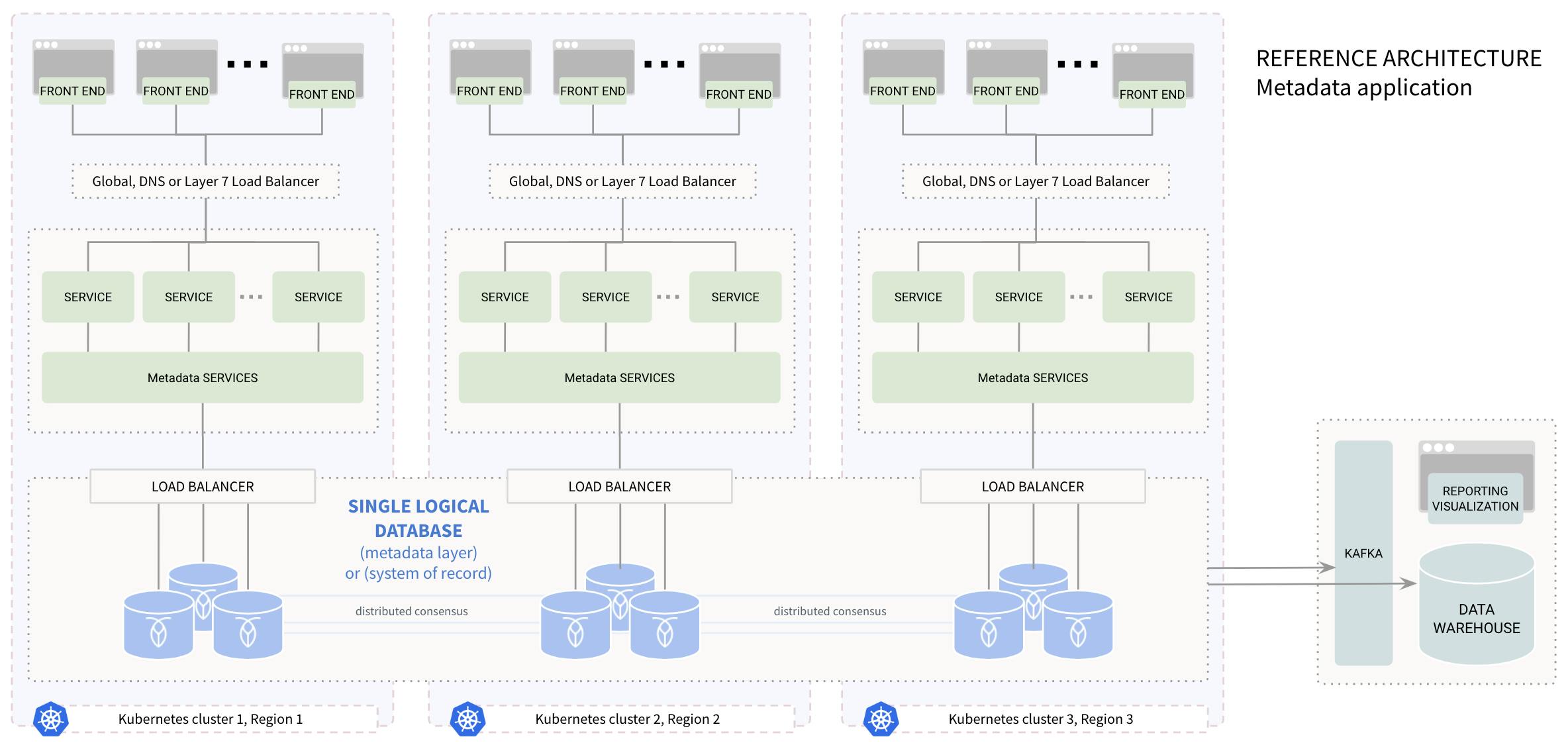
Best practices for user metadata management
Think carefully before you start
Before you even begin building your metadata store, it pays to think very carefully about your needs now, as well as your likely needs for the foreseeable future. Here are a few questions to consider (but don’t limit yourself to just these):
- Where will you store your user metadata? Separate columns in the
userstable? A separatemetadatatable linked tousers? Multiple separate metadata tables for different types of metadata? The answer will depend on your expected patterns of usage, but in general, the bigger you scale the more you’ll want to keep things separate so that (for example) a frequently-updated piece of metadata isn’t bogging down performance for other application services that need to access theuserstable. - How many users do you have, or expect to have? This will affect everything from the way you design your metadata store to the database that powers it. At enterprise scale, you should be thinking about data distribution, and how you’ll maintain consistency across distributed database nodes. Speaking of distribution…
- Where are those users? Some products may be highly local, but enterprise scale usually means global scale, and that typically means that you’ll need a way to geolocate your data. This will be necessary both for regulatory compliance and to maintain a reasonable latency for users. Speaking of latency…
- What are your SLAs? How much latency is acceptable? How much downtime is acceptable? How much data loss is acceptable in the event of an outage? The answers to these questions will vary. Data loss is rarely acceptable, but in some industries, 45 minutes of planned downtime might be OK. In others, two minutes of downtime could be a PR disaster.
Perhaps needless to say, it pays to be forward-thinking here. Building for scale from the beginning is much easier than trying to weld it onto your system further down the line, so we suggest erring on the side of optimism when it comes to your anticipated scale.
Ensure high availability
If your user metadata store goes offline, it will almost certainly either degrade your application experience or effectively render the application offline from a user perspective, since any features that make use of user metadata simply won’t work.
In the context of any database at scale, high availability almost certainly means a distributed system. Hardware failures, power outages, water leaks that lead to fires](https://thenewstack.io/paris-is-drowning-gcps-region-failure-in-age-of-operational-resilience/) – there is simply no escaping entropy, and thus, your metadata store cannot have a single point of failure.
Of course, implementing a distributed database brings a host of new potential complications. NoSQL databases, for example, are great at distributing data, but typically cannot offer strong consistency between nodes, meaning that the scenario we described at the beginning – in which a player buys an item but can’t see it in her inventory – can still occur. SQL databases offer strong consistency, but manual sharding can quickly become an expensive nightmare.
There is a best-of-both-worlds option here – distributed SQL databases – but even there, expect a learning curve, as the best practices for performance with a distributed SQL database are different from single-instance SQL databases.
Localize your data
As mentioned earlier, data localization is often a regulatory requirement for global enterprises, as different countries have different laws pertaining to the storage and transmission of user data, and many require storing a user’s data in the country where they reside.
Even if your company operates only in a single country such as the United States, though, there are good reasons to localize. It’s likely that almost every user interaction in your application accesses or records some metadata. If that means the data has to do a cross-country round-trip, that latency will add up fast. Geolocating your user metadata will allow you to place it closer to where the users actually are, improving the speed of your application.
And of course, there are also state-level regulatory requirements to consider.
Manage access carefully
It is critically important to control who has access to the metadata database, and to manage user permissions within your own organization accordingly.
It’s possible for a single bad query or deleted index to degrade performance across the entire database, bottlenecking the entire application as a result. It is not difficult for this to happen accidentally, especially if a large number of people have the access required to make these changes.
The best practice here is to keep access to the production metadata store as limited as possible. While this database likely considers data that will be of interest to a variety of company departments such as analytics and marketing, data should be synced to a separate data warehouse for this purpose.
It’s also important to maintain detailed access logs so in the event that (for example) a bad query does bog down your system, it’s easy to quickly see what query it was and where it came from. (Modern databases such as CockroachDB come with observability features to make this task simple).
Standardize and document
Metadata stores tend to be massive, particularly for companies at enterprise scale. It’s critical to enforce standards both systemically (via your schema) and organizationally (via team norms and practices).
Documenting your schema, creating a detailed data dictionary, and normalizing the language that your team and company use internally to describe various elements of your user metadata will help keep things organized and facilitate the onboarding of new team members as your company grows.
Ensure data integrity with strong consistency
Distributed databases are required to live up to some of the other best practices on this list, such as maintaining availability and localizing data. But not all distributed databases offer the same level of consistency.
The precise level of consistency required for your application may depend somewhat on your business and the specifics of your deployment – latency can be a factor here, too. But generally speaking, the “eventual consistency” offered by distributed NoSQL databases isn’t good enough. To return again to our gaming example, when a player purchases an in-game item, she doesn’t want to see it in her inventory eventually; she wants to see it now.
The same is true for users of almost any application; they expect the records of their interactions to be available instantly. When they aren’t, it erodes trust and increases the chances they’ll churn.
Monitor and optimize performance
Along with monitoring access, it’s critical to monitor, log, optimize, and re-optimize performance as your company grows. A query that works well at one million users might not be optimal when you hit a hundred million. Plus, usage patterns and features change over time.
Most modern databases come with built-in monitoring tools, so this is typically just a question of setting up alerts, building a cadence for regular check-ins, and making optimizations when they’re needed as things change over time.
Encrypt PII at rest and in flight
This one likely goes without saying, but it’s so important that we’ll say it anyway. Whatever enterprise database you’re using, there are options for encryption both at rest and in flight available. Use them.
User metadata stores almost always contain personally identifiable information (PII), so this isn’t just a best practice – depending on your industry and the locations you do business in, it is likely to be a legal requirement.
It’s also a good idea to conduct regular security audits to make sure that all data is being properly stored and secured.
Keep up with updates
Updating your database can be intimidating. Even innovative companies fall prey to the “if it ain’t broke, don’t fix it” mindset when it comes to their user metadata stores and other mission-critical database workloads. Traditionally, updating SQL database software has also meant taking the database offline – an unappealing prospect, to put it mildly.
[fake screenshot - app alert of scheduled downtime]
But skipping updates means missing out on performance improvements, potentially helpful new features, and (sometimes) important security patches. And modern distributed SQL databases such as CockroachDB can execute rolling software updates in the background, without any need to take the database offline.
The same principle applies to your database schema, too. While it’s best to keep changes to your user metadata schema to a minimum, changes from time to time are inevitable. And while that also used to mean taking your database offline, CockroachDB can execute these online as well, enabling you to make schema changes in a timely fashion without impacting the user experience.
Make schema changes additive
When you do have to change the schema, it’s best to make these changes additive. This does introduce the challenge of how you’ll backfill the data for the columns you’re adding into existing rows in your metadata store. But the alternative – removing elements of your schema – means that any aspects of your application that accessed any part of the removed data will break. Unless you can be very sure you’ve foreseen all of the potential issues with removing something from your schema, it’s probably best not to.
And while backfilling data can be a hassle, depending on the nature of the data it may be a process that you can execute gradually in the background over time, rather than having to prepare and insert all of it at the same moment you make the schema change.
Metadata: the invisible hero
Ultimately, the goal of a user metadata store is to be invisible. As we’ve outlined throughout this post, the way you build and configure your metadata store and the database software that runs it can all have a significant impact on how users experience your application. But ultimately, one of the surest signs that you’ve done things right is that nobody notices you’ve done anything at all.
