
CockroachDB offers a number of powerful enterprise features, most notably those related to geo-partitioning tables. Geo-partitioning allows users to control where their data lives geographically, at the row-level. To make geo-partitioning easier for users to try out, we made some updates to cockroach demo that enable you to check out enterprise features without the need for a full deployment. Note that all of the features discussed in this blog will be available in CockroachDB version 19.2.
When you run cockroach demo in a terminal, CockroachDB starts a temporary, in-memory cluster, and then opens a SQL shell to that cluster. The in-memory cluster persists only as long as the shell is open, and the data is lost once the shell is closed. cockroach demo also automatically acquires a temporary enterprise license for each demo session, so you can use enterprise CockroachDB features right now. After you install CockroachDB, no further set up is necessary. So let’s dive right into the new features available for use with cockroach demo!
To get started, simply run cockroach demo from the command line.
After you start up cockroach demo, you’ll notice that the movr database is preloaded to the demo cluster. This database contains several pre-populated tables that store user, ride, and vehicle data for the global fictional vehicle-sharing company MovR. For MovR to service users all over the world, its database should be used on a distributed multi-region and multi-node deployment of CockroachDB. Take a look at how some new additions to cockroach demo can make setting up a virtual multi-region application easy.
The first requirement for a distributed, multi-region cockroach cluster is to have more than one cockroach node. Using the --nodes <N> flag to cockroach demo, you can spin up an n-node in-memory cockroach cluster. For example, to start up a 9-node cluster, run the following command:
$ ./cockroach demo --nodes 9On this 9-node demo cluster, you can use EXPLAIN statements to get a more detailed look at how queries are planned and executed across the different nodes. To look at the distributed plan for a query, use the EXPLAIN (DISTSQL) prefix before the query. This returns a URL containing an interactive visualization of the query plan. For example, suppose you wanted to find all users who own vehicles by joining the vehicles and users tables where the vehicle owner_id and user id columns are equal.
> EXPLAIN(DISTSQL) SELECT * FROM vehicles JOIN users ON vehicles.owner_id = users.id
automatic | url
+-----------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
true | https://cockroachdb.github.io/distsqlplan/decode.html#eJzEk0GL2zAQhe_9FWFOuzBLLFnb7hoKc-z2sClpb8UHxZrGBscyklwaSv57sR2IHRI3bqE9WjPfmzfz8E-orOFXvWMPyVcQgPAECM-QItTOZuy9dW2pb3wxPyCJEIqqbkL_HIpQMiTQVNYZdmwAwXDQRdnW00OKkFnHkJxaX-2DrZfqrBHBNuEomyL4oLcMiTrgYLQYjL4g_EVvSl6zNuyW0UgealfstNvTd86LrGQPCJ9rXflk8QDj2Se5zX6Ra5-PhUhBt9TRn7jq7_enwT-63gft84-2qNgt5dhayd_CHan7967Y5uGOxD0grJqQLEggSaQYSSE9Ir1Feof0hPSMJCIkIZCERBIxXAsiHi0qbw9CXA6i8ez-IgUxSkFeNfcPUoj_WwrRdApr9rWtPN_0o0Xtlmy23F_N28Zl_MnZrBvTf646rnsw7ENffew_Xqq-1BocwuIcFkNYjmAxD1bTsJy0HU3D8Qzbch6spmE1y3Z6ePMrAAD__8ep3nk=
(1 row)
The visual execution plan shows you some different components of the execution plan, including components that read rows from the tables, and other components that perform a Hash Join. You can also see how the query is distributed among nodes in the cluster. Nodes 8 and 9 perform the read and join, and then stream their data to node 1.
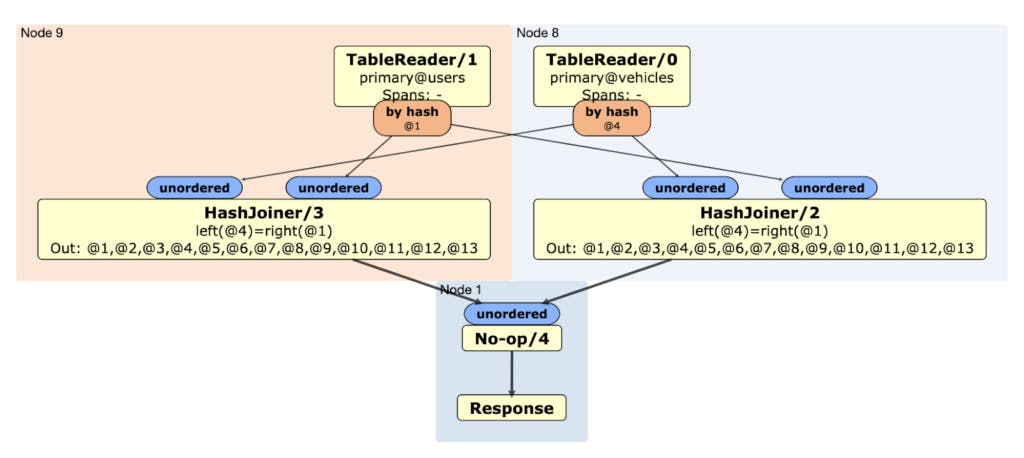
In order to distribute the movr dataset across multiple regions, the CockroachDB nodes need to know where they are located geographically, or perhaps what kind of hardware they have access to. You can assign locality information, like regions and availability zones, to each node in the demo by using the --demo-locality flag. Make a 9-node demo cluster, where each node is virtually located in a different region in the US and Europe, with different availability zones:
$ ./cockroach demo --nodes 9 --demo-locality=region=us-east1,az=b:region=us-east1,az=c:region=us-east1,az=d:region=us-west1,az=a:region=us-west1,az=b:region=us-west1,az=c:region=europe-west1,az=b:region=europe-west1,az=c:region=europe-west1,az=d
…
> SELECT node_id, locality FROM crdb_internal.gossip_nodes;
node_id | locality
+---------+--------------------------+
1 | region=us-east1,az=b
2 | region=us-east1,az=c
3 | region=us-east1,az=d
4 | region=us-west1,az=a
5 | region=us-west1,az=b
6 | region=us-west1,az=c
7 | region=europe-west1,az=b
8 | region=europe-west1,az=c
9 | region=europe-west1,az=d
(9 rows)
If you don’t specify localities for each node in your cluster, cockroach demo automatically assigns some location information for you.
$ ./cockroach demo --nodes 9
…
node_id | locality
+---------+--------------------------+
1 | region=us-east1,az=b
2 | region=us-east1,az=c
3 | region=us-east1,az=d
4 | region=us-west1,az=a
5 | region=us-west1,az=b
6 | region=us-west1,az=c
7 | region=europe-west1,az=b
8 | region=europe-west1,az=c
9 | region=europe-west1,az=d
(9 rows)
The default locality settings mimic a Google Cloud Platform multi-region cluster in the US and Europe, where each node belongs to a different availability zone within each region. The default location information is also connected to the Admin UI’s Node Map. Go to the Admin UI in your browser, and see the nodes and their locations in the map. To open the Admin UI, go to the URL that appears when cockroach demo starts up.
$ ./cockroach demo --nodes 9
#
# Welcome to the CockroachDB demo database!
#
# You are connected to a temporary, in-memory CockroachDB cluster of 9 nodes.
#
# This demo session will attempt to enable enterprise features
# by acquiring a temporary license from Cockroach Labs in the background.
# To disable this behavior, set the environment variable
# COCKROACH_SKIP_ENABLING_DIAGNOSTIC_REPORTING=true.
#
# The cluster has been preloaded with the "movr" dataset
# (MovR is a fictional vehicle sharing company).
#
# Reminder: your changes to data stored in the demo session will not be saved!
#
# Web UI: http://127.0.0.1:58004
#
# Server version: CockroachDB CCL v19.2.0-alpha.20190606-2479-gd98e0839dc (x86_64-apple-darwin18.7.0, built 2019/09/25 15:18:08, go1.12.6) (same version as client)
# Cluster ID: 98a34894-80ea-4ffb-8f0d-9b2a300edca9
# Organization: Cockroach Demo
#
# Enter \? for a brief introduction.
#
...
Without any geo-partitioning, the data in our multi-region 9 node cluster is distributed across the globe, and, with enough data, some of the tables could have rows in all 3 of the regions!
In CockroachDB, tables are separated into ranges of data, each containing up to 64 MB of contiguous data. After the data is split up into ranges, the ranges are then distributed among the nodes in the cluster, and operations on ranges are distributed to the nodes that hold the ranges. You can use the SHOW RANGES command to show information about the ranges in a database, including the nodes that they are running on and the size of ranges.
> SHOW RANGES FROM DATABASE movr;
table_name | start_key | end_key | range_id | range_size_mb | lease_holder | lease_holder_locality | replicas | replica_localities
+----------------------------+-----------+---------+----------+---------------+--------------+--------------------------+----------+----------------------------------------------------------------------------+
promo_codes | NULL | NULL | 25 | 0.229083 | 8 | region=europe-west1,az=c | {1,6,8} | {"region=us-east1,az=b","region=us-west1,az=c","region=europe-west1,az=c"}
rides | NULL | NULL | 23 | 0.175825 | 9 | region=europe-west1,az=d | {2,4,9} | {"region=us-east1,az=c","region=us-west1,az=a","region=europe-west1,az=d"}
user_promo_codes | NULL | NULL | 26 | 0 | 9 | region=europe-west1,az=d | {1,5,9} | {"region=us-east1,az=b","region=us-west1,az=b","region=europe-west1,az=d"}
users | NULL | NULL | 21 | 0.005563 | 4 | region=us-west1,az=a | {2,4,7} | {"region=us-east1,az=c","region=us-west1,az=a","region=europe-west1,az=b"}
vehicle_location_histories | NULL | NULL | 24 | 0.086918 | 5 | region=us-west1,az=b | {1,5,8} | {"region=us-east1,az=b","region=us-west1,az=b","region=europe-west1,az=c"}
vehicles | NULL | NULL | 22 | 0.003585 | 6 | region=us-west1,az=c | {1,6,9} | {"region=us-east1,az=b","region=us-west1,az=c","region=europe-west1,az=d"}
(6 rows)
The replicas column in the output of SHOW RANGES shows that our tables are scattered around the (virtual) globe, but, without any partitioning, this cluster could be very slow to respond to a user’s query. Without telling CockroachDB anything about the layout of the tables, it’s possible for ranges of tables with European users to end up in nodes in the US West region. This would mean that European users’ queries would need to contact nodes in the western United States to get data for the query. The latency for communicating the thousands of miles separating the West Coast and Europe would be on the order of 100 ms, making an end user’s application unresponsive. Using CockroachDB’s geo-partitioning features, you can force data relating to users in Europe, US West and US East to live in each region respectively, so that a user’s request never has to leave the region where it belongs. cockroach demo knows how to automatically apply the Geo-Partitioned Replicas topology onto our 9-node cluster. At a high level, the Geo-Partitioned Replicas topology places all data relating to a region and its replicas in that region to allow for both fast region-specific reads and writes. To set up a 9-node, geo-partitioned demo cluster, simply use the --geo-partitioned-replicas flag on cockroach demo:
$ ./cockroach demo --geo-partitioned-replicasNow take a look at the users table, using the SHOW PARTITIONS command.
> SELECT table_name, partition_name, column_names, partition_value, zone_config FROM [SHOW PARTITIONS FROM TABLE users];
table_name | partition_name | column_names | partition_value | zone_config
+------------+----------------+--------------+-------------------------------------------------+----------------------------------------+
users | us_west | city | ('seattle'), ('san francisco'), ('los angeles') | constraints = '[+region=us-west1]'
users | us_east | city | ('new york'), ('boston'), ('washington dc') | constraints = '[+region=us-east1]'
users | europe_west | city | ('amsterdam'), ('paris'), ('rome') | constraints = '[+region=europe-west1]'
(3 rows)
Time: 75.957ms
As you can see, cockroach demo created 3 partitions of the movr data: us_west, us_east, and europe_west. The us_west partition contains all rows in the users table that have a city value of either seattle, san francisco, or los angeles. Additionally, we see that the us_west partition has a zone_config of +region=us-west1, meaning that data within this partition must live on a node that has the locality attribute region equal to us-west1. This zone configuration places the us_west partition of the users table within the group of nodes in our cluster that “live” in the US West region. Every request to the users table that touches rows with a city value equal to seattle, san francisco or los angeles will never have to leave the US West region! If you look around at other tables in the MovR dataset, you will see that partitions have been applied to the other tables in a similar way, and similar restrictions apply to the partitions us_east and europe_west. To see the exact commands used to apply these partitioning rules upon the tables, you can use the SHOW CREATE <table name> command.
To explore more of the Admin UI post-partitioning, you can run a sample workload against the demo cluster, by adding the --with-load flag when starting the demo cluster. This runs a light workload aimed at mirroring the operations on the database of a vehicle-sharing app, with users starting and stopping rides. After running cockroach demo--with-load, you can navigate to the Admin UI and start to see what your demo cluster looks like under load. In the Admin UI you can explore different statistics about the cluster, such as different percentile query latencies, and range replication information.
With cockroach demo, you can check out some of the work we’ve done this quarter to improve the usability of CockroachDB’s enterprise features. Please take a look and play around, and see if CockroachDB is a good fit for your workload!

