The other week, we devoted an episode of The Cockroach Hour to talk about the dirty secret of isolation levels. When host Jim Walker was titling the webinar, I’m pretty sure he had one particular “secret” in mind: dirty reads. But the conversation kicked off with discussion of an even more pervasive secret: most developers don’t pay attention to isolation levels. Guests Tim Veil and John Sheaffer, both Solutions Engineers at Cockroach Labs, have decades of experience developing against and working with–and for–all sorts of databases. And both of them admitted that for years, they weren’t paying enough attention to what was happening with their applications' consistency models and isolation levels.
I’m not saying this to throw Tim and John under the bus. I’m saying it to illustrate that even very senior devs don’t always understand this topic, because for the most part, it’s easy to ignore. As Tim says in the webinar, most developers think “If the database is up and running, why should I care about isolation levels?”
In this recap of the consistency models webinar, we’ll explore what common database isolation levels mean, and why you should care. It’s an easily and widely misunderstood topic, but one that’s hugely important to security, performance, and most of all: data correctness.
What are ACID transactions & why do they matter?
The conversation started out with a review of ACID semantics, and why they matter. When a database checks off the four components of ACID–atomicity, consistency, isolation, and durability, it’s said to be ACID compliant. ACID compliance guarantees valid database transactions even in the face of unexpected errors, like network errors, hardware failures, and other outages.
At a first look, this characterization can make it sound like all ACID compliant databases are created equal. As they discuss in the webinar, this couldn’t be further from the truth. We’ll dive into the conversation around that in a bit, but first, let’s review what each of the components of ACID means:
A: Transactions are Atomic
Atomicity guarantees that transactions complete (or fail) as atomic units. If a given statement that comprises a transaction fails to complete, the entire transaction will fail.
C: Transactions are Consistent
Consistency requires that all database transactions only affect the data in previously agreed upon rules. These rules vary a lot based on the database’s consistency model (more on this in a bit).
I: Transactions are Isolated
In ACID semantics, isolation is about concurrency control. Depending on the isolation model, it makes different contracts about what happens to your data, and when any changes made by one operation become “visible” to other transactions.
D: Transactions are Durable
Durability guarantees that any updates last. They become permanent and stored in memory.
All four elements need to work in concert. There’s not a lot of wiggle room with the A, C, and D components of ACID. As Tim says in the conversation, you can more or less think of those components as binaries. A transaction is durable, or it’s not. A transaction is isolated, or it’s not. A transaction is atomic, or it’s not.
But when it comes to consistency? That’s a different story. Consistency, unlike the other ACID semantics, is a somewhat hand-wavey spectrum, filled with increasingly more consistency models that it’s really important for developers to understand.
What are Database Isolation Levels?
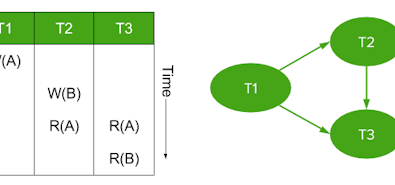
Database isolation levels are a contract by the database about what side effects and anomalies you might see from any given transaction. Some common ones (starting with the strictest level) include serializability, read committed, read uncommitted, and repeatable reads.
These have different implications for your data. For example, a repeatable read isolation level states that once a transaction has read some data, reading it again within the same transaction yields the same results. Concurrent transactions modifying that data have to somehow not affect the execution of our reading transaction. However, this isolation level allows the Phantom Read anomaly. Basically, if a transaction performs a query asking for rows matching a condition twice, the second execution might return more rows than the first. These anomalies have serious implications. Recent research at Stanford has explored the degree to which weak isolation leads to real-world bugs.
CockroachDB’s consistency model is somewhere between serializable and linearizable. If you’re new to this topic and want to go a bit deeper, Wikipedia offers a great overview of database isolation levels, and Jepsen’s consistency models page is another good resource.

Isolation levels map. Source: Jepsen.io
To learn more about how to choose an isolation level that makes sense for your application, watch the full webinar.