Welcome! If you find yourself here wondering What does “serverless database" even mean? you may want to start with Andy Kimball’s introduction to serverless architecture post before coming back to dive in with us here.
On the flip side, if you’re already thinking How ARE you running a serverless database on Kubernetes? Sometimes, my deployments take 10 minutes to fully roll out and my eyes are fully-featured YAML parsers. Theytoldmethiswouldbebetter! — you’ve come to the right blog post.
YAML jokes aside, if you’ve personally wrestled with dynamic scaling in Kubernetes you might feel a bit skeptical of our claims: Namely, that CockroachDB Serverless has fast startup times and that we use Kubernetes. Keep reading to learn the details of exactly how we are deploying stateful Kubernetes workloads for CockroachDB Serverless.
An old Cockroach can learn new tricks
CockroachDB is separated into two layers: SQL and a Key/Value (KV) storage layer. The SQL layer is responsible for parsing, optimizing, and executing queries from users. The KV layer is responsible for storing, retrieving, and distributing data while providing Cockroach’s transactional semantics.
In a dedicated CockroachDB deployment, these two layers communicate in the same process. A multi-tenant deployment takes this separation one step further and splits each layer into its own process. This leaves us with one large stateful cluster of storage pods that acts as the back end for many stateless SQL pods.
This KV Cluster is actually just a dedicated CockroachDB deployment.
If we were to follow our instructions on how to deploy CockroachDB onto Kubernetes, we’d have a ready-to-go Serverless storage layer. While end users can connect directly to these clusters via SQL, that’s not their primary purpose in a multi-tenant deployment. In addition to SQL, every CockroachDB process hosts a gRPC service. This service is used for intra-node communication, powers some of the cockroach CLI, and most importantly exposes access to the KV layer. When executing SQL on behalf of a user, SQL pods will leverage this service to access or modify any persisted data.
SQL pods are where we get into uncharted territory. Much like the storage pods, SQL pods are still CockroachDB, this time with a slightly different entrypoint. Thanks to the architecture of CockroachDB’s SQL execution layer, SQL pods are horizontally scalable. More concretely, this means that we can quite easily control the quality of service tenants experience by adjusting the resource limits and requests on SQL pods, or by modifying the number of replicas allocated to them.
While this is true for the storage layer as well, it doesn’t happen on demand. SQL pods are much more “poddy” in the Kubernetes sense. They are entirely ephemeral and allocated on demand. There could be zero or hundreds of replicas in existence at any point in time.

Low latency resumption
Kubernetes users may already be asking, How can a tenant be accessible in less than a second, if we’re creating new pods for them?!
Those that have anxiously watched as pods spin up for newly released software know that the startup time for a pod can vary quite wildly. When the desired container image is already present, cold start latencies can run anywhere between 10 to 60 seconds. Not exactly a desirable profile for connecting to your application’s database!
In CockroachDB Serverless, we allow SQL Pods to spin up in an un-bound state. That is to say, these pods do not belong to a specific tenant yet. This allows us to use a Kubernetes deployment as a pool of ready and waiting prewarmed pods — and thus avoid pod start up times.
Whenever a tenant needs to connect or scale up, a pod is plucked out of the deployment and then bound to the tenant. The plucking process is done by breaking the deployment’s label selector and changing the pod’s OwnerRef to a CrdbTenant resource, which is a custom resource managed by an operator process within our Kubernetes cluster.
The OwnerRef re-assignment ensures that Kubernetes will garbage collect the SQL pod, should the owning tenant get deleted. The Deployment controller will then handle “warming up” more un-bound pods for us automatically.
Once a SQL Pod is plucked out, it must be “stamped” with its tenant’s identifier. During the stamping process, TLS certificates, which allow a SQL pod to authenticate as a tenant to the KV pods, will be sent to the plucked pod via an HTTPS endpoint. Once the SQL pod has received the certificates, the HTTPS endpoint is shutdown, and the pod begins accepting SQL connections. Finally, a new label, indicating the tenant, is applied to the pod which is used to route incoming connections. This process takes less than a second.

The Autoscaler
Now that we know how to create SQL pods for tenants through the resumption process, how do we know the quantity of such instances we need?
The autoscaler component within the operator decides the number of SQL pods that each tenant needs at any point in time. It does so by monitoring the CPU load across all SQL pods for each tenant in the Kubernetes cluster, and calculates the desired number of SQL pods based on two metrics:
- Average CPU usage during the last 5 minutes
- Peak CPU usage during the last 5 minutes
Our Serverless architecture blog post digs into the mechanics of scaling, so we won’t go into detail here. Note, however, that a special case of resumption (i.e. scaling from 0 to 1) does not get handled by the operator. Instead, the SQL Proxy takes over. This allows suspended tenants to be quickly resumed whenever a new connection is established. (No worries, we’ll discuss the SQL Proxy in more detail further down).
Once the autoscaler knows how many pods to assign to a given tenant, it updates the desired state in the corresponding CrdbTenant resource.
Kubernetes controllers
Let’s look at how changes to the CrdbTenant resources by the autoscaler component actually get applied to the cluster.
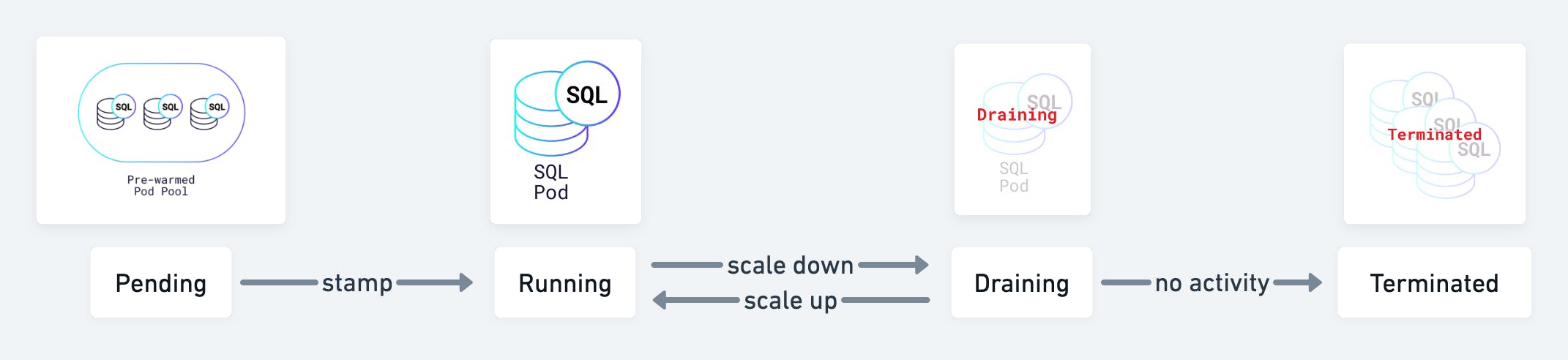
Just like how deployments work, we describe a desired state in a CrdbTenant resource, and a CrdbTenant controller in the operator will update the actual state to the desired state at a controlled rate. In our case, the controller for the CrdbTenant resource will ensure the desired number of SQL pods. If we have too many of them, the reconciler will attempt to drain excess ones. Likewise, if we do not have enough SQL pods, the reconciler will bind more of them through the stamping process described earlier.
SQL pods go through a draining process instead of getting terminated right away so that SQL connections can be terminated more gracefully. When we start supporting connection transfers in the future, eligible connections will be transferred to existing running SQL pods, reducing overall connection breaks. The draining process ends once all connections have been terminated, or once 10 minutes have passed, whichever comes first.
There were a few optimizations that we did here to reduce SQL pods churning:
- When choosing a pod to stamp, we will prioritize pods in the draining state if they have not been terminated yet. These pods will be put back into the running state.
- Reusing existing draining pods prevents constant churning of the unstamped pods in the prewarmed pool, especially when the load fluctuates very frequently.
- This also allows us to limit the number of draining pods in the Kubernetes cluster, reducing overall resource usage by that tenant.
- Similarly, when choosing a SQL pod to drain, we will prioritize pods with a lower CPU usage over higher ones. This allows us to break fewer connections in certain cases.
Pictorially, a SQL pod’s state can be described using the following diagram:
Putting it all together with the SQL Proxy
Now that we know all the fundamentals that support Serverless clusters, it’s time to take a look at the SQL Proxy component. The SQL Proxy component is what end users connect to when they use CockroachDB Serverless.
This component is backed by a Kubernetes deployment, and allows a connection to be routed to corresponding stamped SQL pods. Within the SQL Proxy, there exists a tenant directory component that stores a mapping of cluster identifiers to their stamped SQL pods. This directory is populated by querying the Kubernetes API server, and to reduce the number of API calls, we have an in-memory cache, in addition to Kubernetes watchers. But, how does all of this relate to the experience of connecting to our Serverless clusters?
Let’s dive deeper by using an example of a connection string for a Serverless cluster:
postgresql://user:pass@free-tier.gcp-us-central1.cockroachlabs.cloud:26257/defaultdb?sslmode=...&options=--cluster=max-roach-35'
When we connect to the cluster using the connection string above, we’re actually connecting to one of the SQL Proxy pods within the Kubernetes cluster.
The proxy will extract the cluster identifier provided through the options parameter (here, ‘max-roach-35’) to perform an IP address lookup on the tenant directory. If there are active SQL pods, the proxy will route the SQL connection to one of them based on weighted CPU load balancing.
But what if the autoscaler has already scaled down the SQL pods due to no traffic, resulting in none available for the corresponding tenant? This is where our low-latency resumption process comes in. The proxy updates the CrdbTenant resource of the corresponding tenant to request for one SQL pod.
This operation triggers the Kubernetes reconciliation process, which causes the operator to perform the stamping process for the corresponding tenant. Once the SQL pod is up and running, the proxy can now route the initial SQL connection to it. We’re currently working towards a better connection experience by bringing the resumption time down further.
Conclusion
Now that you have seen how to create SQL pods for tenants through the resumption process, control the number of SQL pods for each tenant with the autoscaler component, and use SQL Proxy to connect with pods in a Serverless Kubernetes cluster, now you can try it for yourself!
Head over to https://cockroachlabs.cloud/signup and get started instantly with a free CockroachDB Serverless account.
If you run into questions, please join us in our Community Slack channel and ask away. We’d also love to hear about your experience with CockroachDB Serverless — we value feedback, both positive and negative. We’ll be working hard to improve it over the coming months, so sign up for an account and get updates on our progress. And if you’d love to help us take CockroachDB to the next level, we’re hiring.
Additional resources
- Free online course: Introduction to Serverless Databases and CockroachDB Serverless. This course introduces the core concepts behind serverless databases and gives you the tools you need to get started with CockroachDB Serverless
- Free downloadable guide: Architecture of a Serverless Database
- Bring us your feedback: Join our Slack community and let us know your thoughts!
- We’re hiring! Join the team building CockroachDB. Remote-friendly, family-friendly, and taking on some of the biggest and most fascinating challenges in data and app development.


