
This page provides recipes for fixing performance issues in your applications.
Problems
This section describes how to use CockroachDB commands and dashboards to identify performance problems in your applications.
| Observation | Diagnosis | Solution |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Solutions
This section provides solutions for common performance issues in your applications.
Transaction contention
Transaction contention is a state of conflict that occurs when:
- A transaction is unable to complete due to another concurrent or recent transaction attempting to write to the same data. This is also called lock contention.
- A transaction is automatically retried because it could not be placed into a serializable ordering among all of the currently-executing transactions. If the automatic retry is not possible or fails, a transaction retry error is emitted to the client, requiring a client application running under
SERIALIZABLEisolation to retry the transaction. This is also called a serialization conflict, or an isolation conflict.
Indicators that your application is experiencing transaction contention
Waiting transaction
These are indicators that a transaction is trying to access a row that has been "locked" by another, concurrent transaction issuing a write or locking read.
- The Active Executions table on the Transactions page (CockroachDB Cloud Console or DB Console) shows transactions with
Waitingin the Status column. You can sort the table by Time Spent Waiting. - Querying the
crdb_internal.cluster_lockstable shows transactions wheregrantedisfalse.
These are indicators that lock contention occurred in the past:
Querying the
crdb_internal.transaction_contention_eventstableWHERE contention_type='LOCK_WAIT'indicates that your transactions have experienced lock contention.- This is also shown in the Transaction Executions view on the Insights page (CockroachDB Cloud Console and DB Console). Transaction executions will display the High Contention insight.
Note:The default tracing behavior captures a small percent of transactions, so not all contention events will be recorded. When investigating transaction contention, you can set the
sql.trace.txn.enable_thresholdcluster setting to always capture contention events.
- This is also shown in the Transaction Executions view on the Insights page (CockroachDB Cloud Console and DB Console). Transaction executions will display the High Contention insight.
The SQL Statement Contention graph (CockroachDB Cloud Console and DB Console) is showing spikes over time.
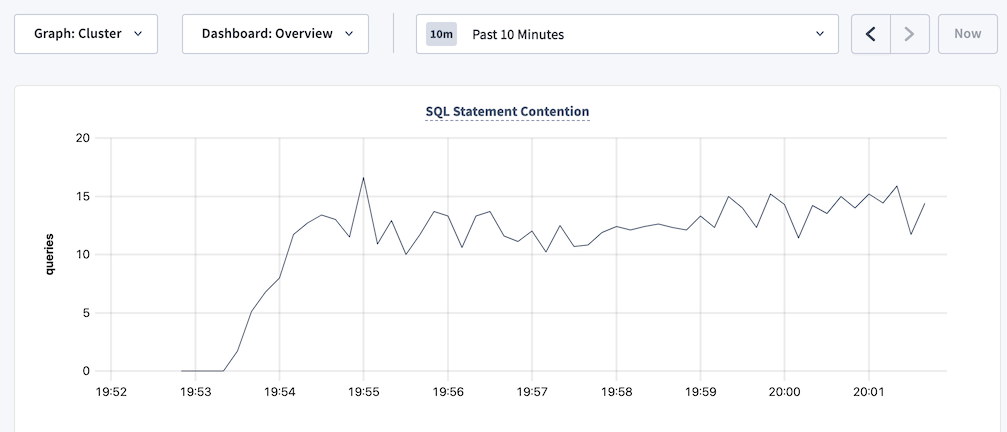
If a long-running transaction is waiting due to lock contention:
- Identify the blocking transaction.
- Evaluate whether you can cancel the transaction. If so, cancel it to unblock the waiting transaction.
- Optimize the transaction to reduce further contention. In particular, break down larger transactions such as bulk deletes into smaller ones to have transactions hold locks for a shorter duration, and use historical reads when possible to reduce conflicts with other writes.
If lock contention occurred in the past, you can identify the transactions and objects that experienced lock contention.
Transaction retry error
These are indicators that a transaction has failed due to contention.
- A transaction retry error with
SQLSTATE: 40001, the stringrestart transaction, and an error code such asRETRY_WRITE_TOO_OLDorRETRY_SERIALIZABLE, is emitted to the client. These errors are typically seen underSERIALIZABLEand notREAD COMMITTEDisolation. - Querying the
crdb_internal.transaction_contention_eventstableWHERE contention_type='SERIALIZATION_CONFLICT'indicates that your transactions have experienced serialization conflicts.- This is also shown in the Transaction Executions view on the Insights page (CockroachDB Cloud Console and DB Console). Transaction executions will display the Failed Execution insight due to a serialization conflict.
These are indicators that transaction retries occurred in the past:
- The Transaction Restarts graph (CockroachDB Cloud Console and DB Console is showing spikes in transaction retries over time.
In most cases, the correct actions to take when encountering transaction retry errors are:
Under
SERIALIZABLEisolation, update your application to support client-side retry handling when transaction retry errors are encountered. Follow the guidance for the specific error type.Take steps to minimize transaction retry errors in the first place. This means reducing transaction contention overall, and increasing the likelihood that CockroachDB can automatically retry a failed transaction.
Fix transaction contention problems
Identify the transactions that are in conflict, and unblock them if possible. In general, take steps to reduce transaction contention.
When running under SERIALIZABLE isolation, implement client-side retry handling so that your application can respond to transaction retry errors that are emitted when CockroachDB cannot automatically retry a transaction.
Identify conflicting transactions
- In the Active Executions table on the Transactions page (CockroachDB Cloud Console or DB Console), look for a waiting transaction (
Waitingstatus).Click the transaction's execution ID and view the following transaction execution details:Tip:If you see many waiting transactions, a single long-running transaction may be blocking transactions that are, in turn, blocking others. In this case, sort the table by Time Spent Waiting to find the transaction that has been waiting for the longest amount of time. Unblocking this transaction may unblock the other transactions.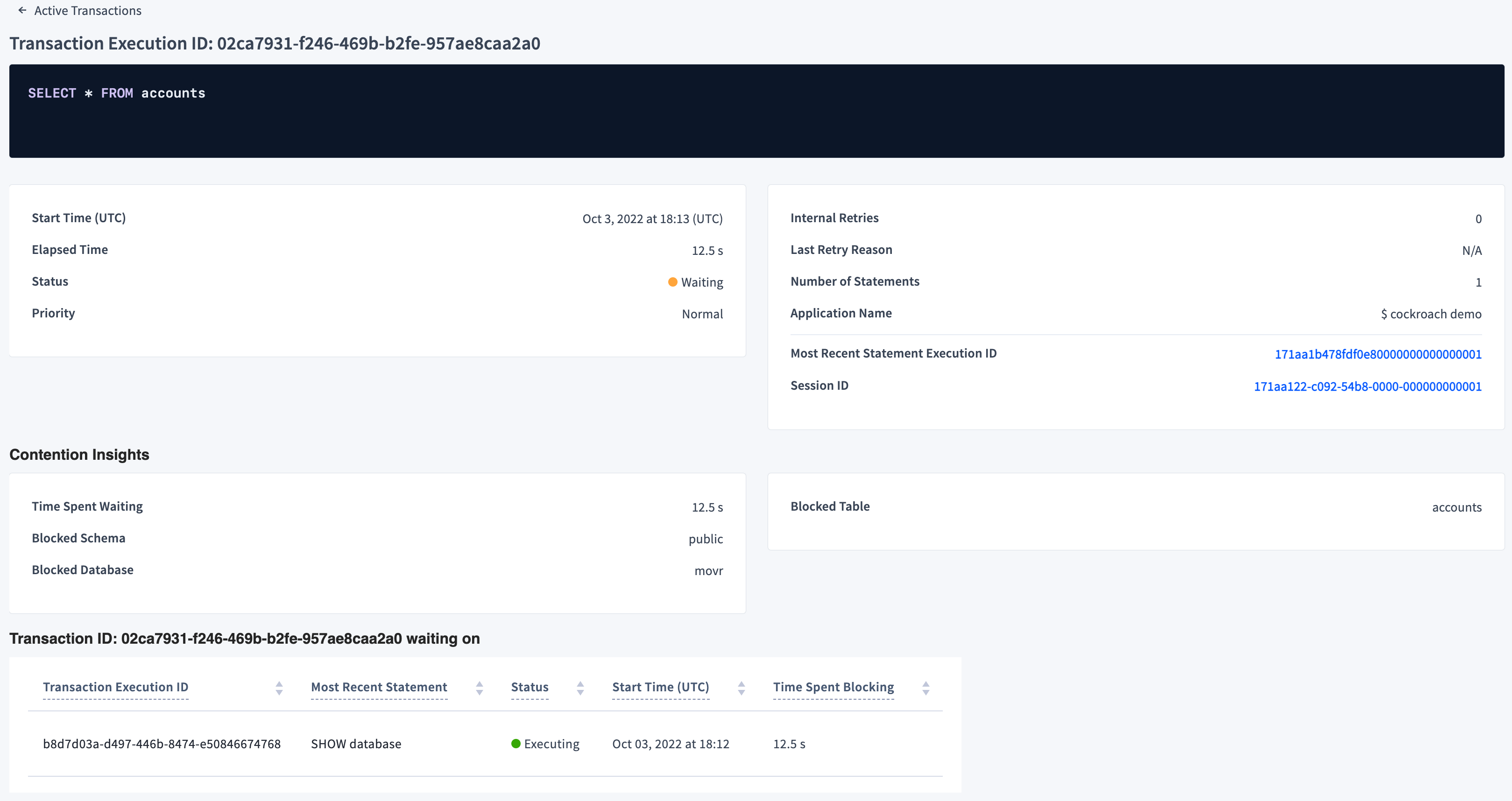
- Last Retry Reason shows the last transaction retry error received for the transaction, if applicable.
- The details of the blocking transaction, directly below the Contention Insights section. Click the blocking transaction to view its details.
Cancel a blocking transaction
- Identify the blocking transaction and view its transaction execution details.
- Click its Session ID to open the Session Details page.
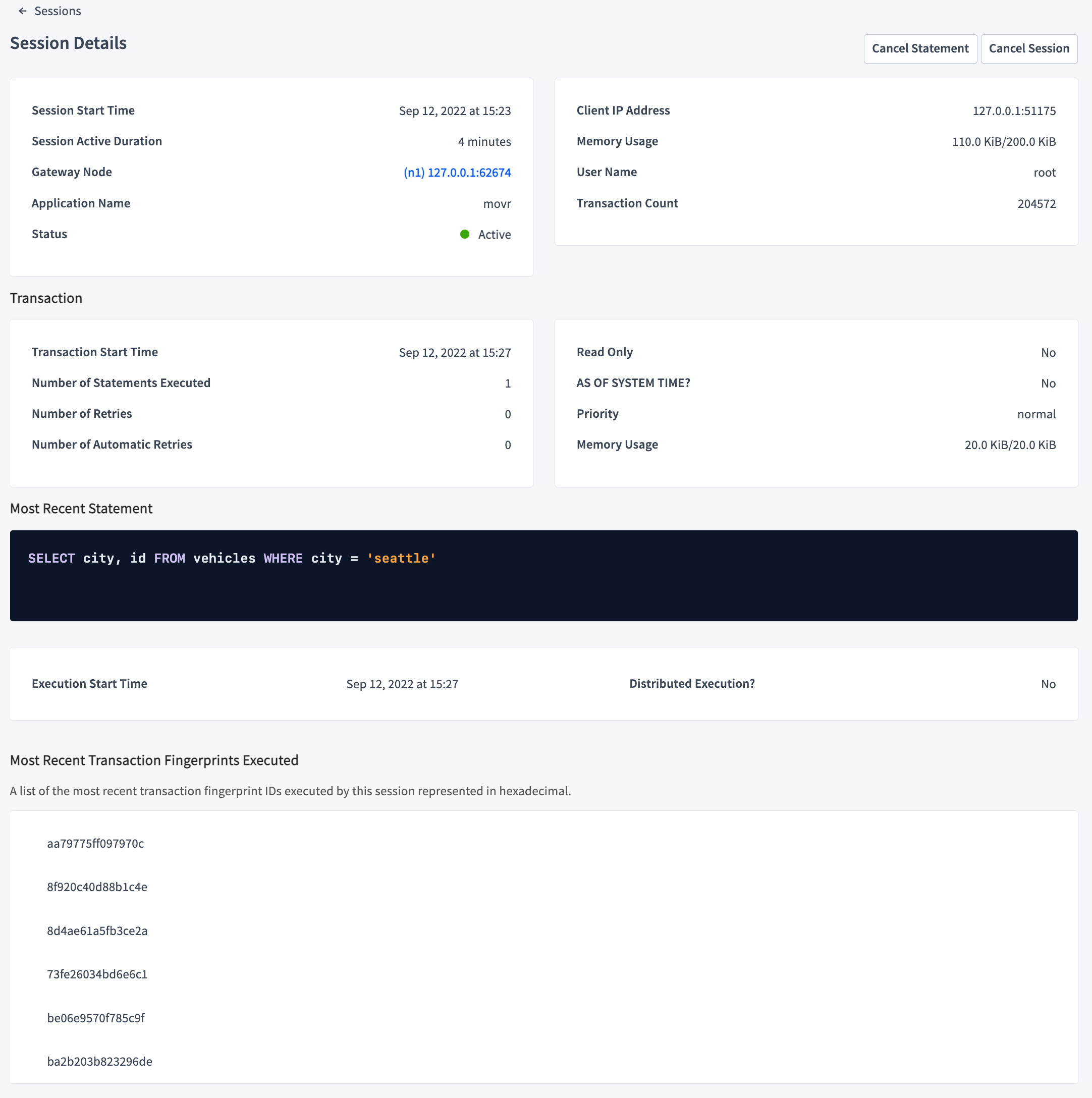
- Click Cancel Statement to cancel the Most Recent Statement and thus the transaction, or click Cancel Session to cancel the session issuing the transaction.
Identify transactions and objects that experienced lock contention
To identify transactions that experienced lock contention in the past:
- In the Transaction Executions view on the Insights page (CockroachDB Cloud Console and DB Console), look for a transaction with the High Contention insight. Click the transaction's execution ID and view the transaction execution details, including the details of the blocking transaction.
- Visit the Transactions page (CockroachDB Cloud Console and DB Console) and sort transactions by Contention Time.
To view tables and indexes that experienced contention:
- Query the
crdb_internal.transaction_contention_eventstable to view transactions that have blocked other transactions. - Query the
crdb_internal.cluster_contended_tablestable to view all tables that have experienced contention. - Query the
crdb_internal.cluster_contended_indexestable to view all indexes that have experienced contention. - Query the
crdb_internal.cluster_contention_eventstable to view the tables, indexes, and transactions with the most time under contention.
Reduce transaction contention
Contention is often reported after it has already resolved. Therefore, preventing contention before it affects your cluster's performance is a more effective approach:
Limit the number of affected rows by following optimizing queries (e.g., avoiding full scans, creating secondary indexes, etc.). Not only will transactions run faster, lock fewer rows, and hold locks for a shorter duration, but the chances of read invalidation when the transaction's timestamp is pushed, due to a conflicting write, are decreased because of a smaller read set (i.e., a smaller number of rows read).
Break down larger transactions (e.g., bulk deletes) into smaller ones to have transactions hold locks for a shorter duration. For example, use common table expressions to group multiple clauses together in a single SQL statement. This will also decrease the likelihood of pushed timestamps. For instance, as the size of writes (number of rows written) decreases, the chances of the transaction's timestamp getting bumped by concurrent reads decreases.
Use
SELECT FOR UPDATEto aggressively lock rows that will later be updated in the transaction. Updates must operate on the most recent version of a row, so a concurrent write to the row will cause a retry error (RETRY_WRITE_TOO_OLD). Locking early in the transaction forces concurrent writers to block until the transaction is finished, which prevents the retry error. Note that this locks the rows for the duration of the transaction; whether this is tenable will depend on your workload. For more information, see When and why to useSELECT FOR UPDATEin CockroachDB.Use historical reads (
SELECT ... AS OF SYSTEM TIME), preferably bounded staleness reads or exact staleness with follower reads when possible to reduce conflicts with other writes. This reduces the likelihood ofRETRY_SERIALIZABLEerrors as fewer writes will happen at the historical timestamp. More specifically, writes' timestamps are less likely to be pushed by historical reads as they would when the read has a higher priority level. Note that if theAS OF SYSTEM TIMEvalue is below the closed timestamp, the read cannot be invalidated.When replacing values in a row, use
UPSERTand specify values for all columns in the inserted rows. This will usually have the best performance under contention, compared to combinations ofSELECT,INSERT, andUPDATE.If applicable to your workload, assign column families and separate columns that are frequently read and written into separate columns. Transactions will operate on disjoint column families and reduce the likelihood of conflicts.
As a last resort, consider adjusting the closed timestamp interval using the
kv.closed_timestamp.target_durationcluster setting to reduce the likelihood of long-running write transactions having their timestamps pushed. This setting should be carefully adjusted if no other mitigations are available because there can be downstream implications (e.g., historical reads, change data capture feeds, statistics collection, handling zone configurations, etc.). For example, a transaction A is forced to refresh (i.e., change its timestamp) due to hitting the maximum closed timestamp interval (closed timestamps enable Follower Reads and Change Data Capture (CDC)). This can happen when transaction A is a long-running transaction, and there is a write by another transaction to data that A has already read.
If you increase the kv.closed_timestamp.target_duration setting, it means that you are increasing the amount of time by which the data available in Follower Reads and CDC changefeeds lags behind the current state of the cluster. In other words, there is a trade-off here: if you absolutely must execute long-running transactions that execute concurrently with other transactions that are writing to the same data, you may have to settle for longer delays on Follower Reads and/or CDC to avoid frequent serialization errors. The anomaly that would be exhibited if these transactions were not retried is called write skew.
Hot spots
Hot spots are a symptom of resource contention and can create problems as requests increase, including excessive transaction contention.
Indicators that your cluster has hot spots
- The CPU Percent graph on the Hardware and Overload dashboards (DB Console) shows spikes in CPU usage.
- The Hot Ranges list on the Hot Ranges page (DB Console) displays a higher-than-expected QPS for a range.
- The Key Visualizer (DB Console) shows ranges with much higher-than-average write rates for the cluster.
If you find hot spots, use the Range Report and Key Visualizer to identify the ranges with excessive traffic. Then take steps to reduce hot spots.
Reduce hot spots
Use index keys with a random distribution of values, so that transactions over different rows are more likely to operate on separate data ranges. See the SQL FAQs on row IDs for suggestions.
Place parts of the records that are modified by different transactions in different tables. That is, increase normalization. However, there are benefits and drawbacks to increasing normalization.
Benefits of increasing normalization:
- Can improve performance for write-heavy workloads. This is because, with increased normalization, a given business fact must be written to one place rather than to multiple places.
- Allows separate transactions to modify related underlying data without causing contention.
- Reduces the chance of data inconsistency, since a given business fact must be written only to one place.
- Reduces or eliminates data redundancy.
- Uses less disk space.
- Can improve performance for write-heavy workloads. This is because, with increased normalization, a given business fact must be written to one place rather than to multiple places.
Drawbacks of increasing normalization:
- Can reduce performance for read-heavy workloads. This is because increasing normalization results in more joins, and can make the SQL more complicated in other ways.
- More complex data model.
In general:
- Increase normalization for write-intensive and read/write-intensive transactional workloads.
- Do not increase normalization for read-intensive reporting workloads.
If the application strictly requires operating on very few different index keys, consider using
ALTER ... SPLIT ATso that each index key can be served by a separate group of nodes in the cluster.If you are working with a table that must be indexed on sequential keys, consider using hash-sharded indexes. For details about the mechanics and performance improvements of hash-sharded indexes in CockroachDB, see the blog post Hash Sharded Indexes Unlock Linear Scaling for Sequential Workloads. As part of this, we recommend doing thorough performance testing with and without hash-sharded indexes to see which works best for your application.
To avoid read hot spots:
- Increase data distribution, which will allow for more ranges. The hot spot exists because the data being accessed is all co-located in one range.
Increase load balancing across more nodes in the same range. Most transactional reads must go to the leaseholder in CockroachDB, which means that opportunities for load balancing over replicas are minimal.
However, the following features do permit load balancing over replicas:
- Global tables.
- Follower reads (both the bounded staleness and the exact staleness kinds).
In these cases, more replicas will help, up to the number of nodes in the cluster.
Statements with full table scans
Full table scans often result in poor statement performance.
Indicators that your application has statements with full table scans
The following query returns statements with full table scans in their statement plan:
SHOW FULL TABLE SCANS;The following query against the
crdb_internal.node_statement_statisticstable returns results:SELECT count(*) as total_full_scans FROM crdb_internal.node_statement_statistics WHERE full_scan = true;Viewing the statement plan on the Statement Fingerprint page in the DB Console indicates that the plan contains full table scans.
The statement plans returned by the
EXPLAINandEXPLAIN ANALYZEcommands indicate that there are full table scans.The Full Table/Index Scans graph in the DB Console is showing spikes over time.
Fix full table scans in statements
Not every full table scan is an indicator of poor performance. The cost-based optimizer may decide on a full table scan when other index or join scans would result in longer execution time.
Examine the statements that result in full table scans and consider adding secondary indexes.
In the DB Console, visit the Schema Insights tab on the Insights page and check if there are any insights to create missing indexes. These missing index recommendations are generated based on slow statement execution. A missing index may cause a statement to have a suboptimal plan. If the execution was slow, based on the insights threshold, then it's likely the create index recommendation is valid. If the plan had a full table scan, it's likely that it should be removed with an index.
Also see Table scans best practices.
Suboptimal primary keys
Indicators that your tables are using suboptimal primary keys
- The Hardware metrics dashboard in the DB Console shows high resource usage per node.
- The Problem Ranges report on the Advanced Debug page in the DB Console indicates a high number of queries per second on a subset of ranges or nodes.
Fix suboptimal primary keys
Evaluate the schema of your table to see if you can redistribute data more evenly across multiple ranges. Specifically, make sure you have followed best practices when selecting your primary key.
If your application with a small dataset (for example, a dataset that contains few index key values) is experiencing resource contention, consider splitting your tables and indexes to distribute ranges across multiple nodes to reduce resource contention.
Slow writes
Indicators that your tables are experiencing slow writes
If the Overview dashboard in the DB Console shows high service latency when the QPS of INSERT and UPDATE statements is high, your tables are experiencing slow writes.
Fix slow writes
Secondary indexes can improve application read performance. However, there is overhead in maintaining secondary indexes that can affect your write performance. You should profile your tables periodically to determine whether an index is worth the overhead. To identify infrequently accessed indexes that could be candidates to drop, do one of the following:
- In the DB Console, visit the Schema Insights tab on the Insights page and check if there are any insights to drop unused indexes.
- In the DB Console, visit the Databases page and check databases and tables for Index Recommendations to drop unused indexes.
Run a join query against the
crdb_internal.index_usage_statisticsandcrdb_internal.table_indexestables:SELECT ti.descriptor_name as table_name, ti.index_name, total_reads, last_read FROM crdb_internal.index_usage_statistics AS us JOIN crdb_internal.table_indexes ti ON us.index_id = ti.index_id AND us.table_id = ti.descriptor_id ORDER BY total_reads ASC;table_name | index_name | total_reads | last_read -----------------------------+-----------------------------------------------+-------------+-------------------------------- vehicle_location_histories | vehicle_location_histories_pkey | 1 | 2021-09-28 22:59:03.324398+00 rides | rides_auto_index_fk_city_ref_users | 1 | 2021-09-28 22:59:01.500962+00 rides | rides_auto_index_fk_vehicle_city_ref_vehicles | 1 | 2021-09-28 22:59:02.470526+00 user_promo_codes | user_promo_codes_pkey | 456 | 2021-09-29 00:01:17.063418+00 promo_codes | promo_codes_pkey | 910 | 2021-09-29 00:01:17.062319+00 vehicles | vehicles_pkey | 3591 | 2021-09-29 00:01:18.261658+00 users | users_pkey | 5401 | 2021-09-29 00:01:18.260198+00 rides | rides_pkey | 45658 | 2021-09-29 00:01:18.258208+00 vehicles | vehicles_auto_index_fk_city_ref_users | 87119 | 2021-09-29 00:01:19.071476+00 (9 rows)Use the values in the
total_readsandlast_readcolumns to identify indexes that have low usage or are stale and can be dropped.
Too many MVCC values
Indicators that your tables have too many MVCC values
In the Databases page in the DB Console, the Tables view shows the percentage of live data for each table. For example:
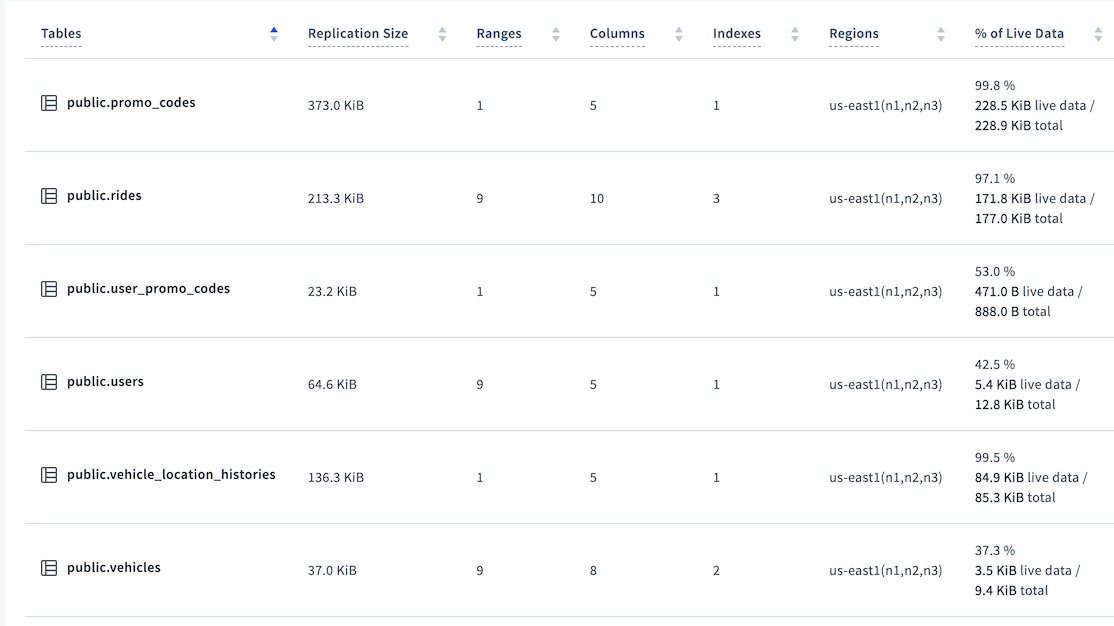
In this example, at 37.3% the vehicles table would be considered to have a low percentage of live data. In the worst cases, the percentage can be 0%.
A low percentage of live data can cause statements to scan more data (MVCC values) than required, which can reduce performance.
Configure CockroachDB to purge MVCC values
Reduce the gc.ttlseconds zone configuration of the table as much as possible.
See also
If you aren't sure whether SQL query performance needs to be improved, see Identify slow queries.
