Slow applications kill business. Greg Lindon (in this now archived deck), noted that 100ms in latency lowered Amazon’s sales by 1%. Marissa Mayer pointed out that speed really matters when she explained the results of A/B tests as “500ms of additional load time dropped Google searches by 20%.”
If slow applications kill the user experience, what about applications that go down due to natural disasters, human error, or a cyber attack? It can be surprisingly common for applications to lose access to cloud data centers. For example, a U.S. financial services company recently shared with us a story about a natural disaster that came within a handful of miles of taking out their two data centers.
Finally, governments worldwide have enacted data domiciling legislation aimed at keeping user data close to the user and restricting access to that data. Data domiciling requirements can force developers to create multiple logically equivalent copies of a database and add complicated logic to their applications to route traffic to the appropriate database. More databases mean more tedious, duplicative, and error-prone work, making it hard for developers to create applications to serve users in multiple regions.
Whether it’s the increased fault tolerance to ensure that your services never go down or improved quality via lower latency in expanding markets or complying with data-domiciling regulations, any business could benefit from a multi-region application. So why, then, do so many applications continue to languish in single-region deployments?
Because multi-region applications have never been easy to build or deploy. In this piece, we will cover how CockroachDB makes it easy to build a multi-region application in three steps.
How CockroachDB (finally) makes multi-region easy
CockroachDB is built from the ground up to bring the scale and resilience of multi-region architecture to everyone, from hobby developers to the largest enterprises. You can deploy CockroachDB anywhere (e.g., self-hosted data centers, cloud-run data centers, multi-cloud deployments). But building multi-region applications has been significantly complex.
We wanted to make multi-region applications possible for any development team – so easy that anyone could leverage the scale and resilience previously reserved for the Netflixes and Googles of the world. With CockroachDB, you can now build and deploy an application across multiple regions in three steps:
- Deploy your application into multiple regions with no required changes.
- Deploy your database into multiple regions.
- Optionally enhance your table patterns for your latency needs.
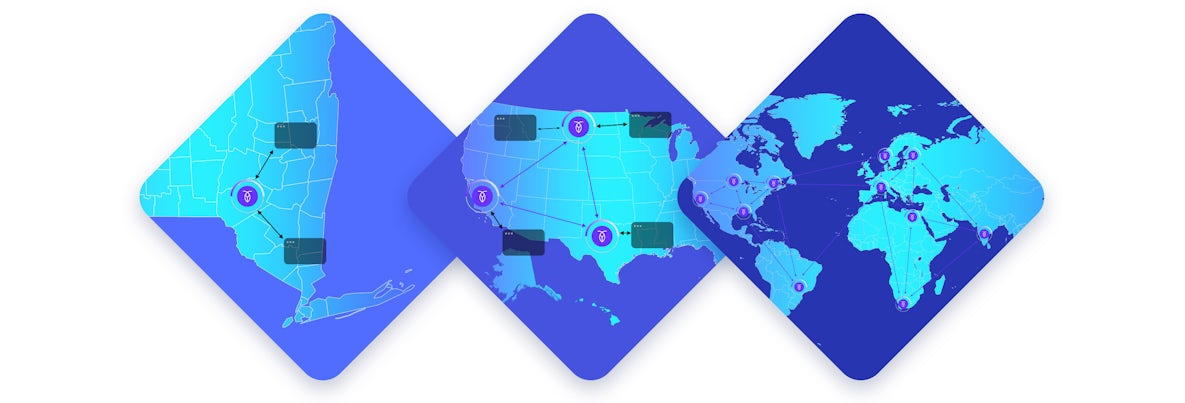
1. Deploy your application into multiple regions
Most applications begin life in a single region with a single-region database. This pattern provides excellent latency to users in the same region, but it can be very slow when accessed from geographically distanced users. The first step in any multi-region application is to deploy your application into multiple regions, preferably with HTTP caching and global load balancing where appropriate.
Deploying an existing application in multiple regions can be the most reasonably straightforward pattern of providing improved scale and resilience, but what about the database? If your database isn’t deployed in multiple regions, you are still susceptible to a single failure domain, and users’ experience outside of the database’s region will be poor.
2. Deploy your database into multiple regions
CockroachDB does not require you to change your application to evolve from a single region to a multi-region application. If legacy databases could even support multi-region applications, and many cannot, they would require you to change your application to make it multi-region.
As with sharding, other databases require the multi-region application to be aware of its deployed region to pass this information back to the database. Legacy databases might require salting or hashing region information and passing it down to the database. It can be tough to do this correctly, and it means spending significant developer time re-writing both the application and the database.
Without this awareness, it would be hard to evaluate global uniqueness. For example, which region does a user live within? Without passing region information in a WHERE predicate clause for a query, region information that the application needs to obtain to create a query, developers would be forced to perform a uniqueness check for each region in the database. This check will introduce costly latency and lower the user experience, which can have debilitating effects for authentication or other modern microservices.
Cluster and Database Regions
CockroachDB makes it easy to deploy your database into multiple regions. Simply set region information for each node in the cluster at startup using node startup locality options:
cockroach start --locality=region=us-east-1,zone=us-east-1b # ...
CockroachDB Dedicated makes this even more accessible as we set locality flags for each multi-region cluster for you automatically based on your chosen cloud provider (e.g., AWS us-east, GCP europe-west1).
The regions added during node startup become Database Regions when they are added to a database. To add the first region to a database, use the ALTER DATABASE ... PRIMARY REGION statement. You can, of course, create a multi-region database from the very beginning via CREATE DATABASE ...PRIMARY REGION. To add another database region, use the ALTER DATABASE ... ADD REGION statement.
That’s it.
You don’t have to do anything else to make your application and the database that powers it multi-region.
By default, CockroachDB will provide low-latency reads and writes for all tables in your database from the first region, the primary region added to the database. Therefore, it is easy to scale your cluster to multiple regions by adding new regions, all without impacting the existing users. They will see the same read and write latency as a single-region database after adding new regions.
CockroachDB will also ensure that you automatically survive the loss of any individual node or availability zone (provided you have at least three or more nodes) without any manual configuration.
3. Enhance Your Multi-Region Database
CockroachDB would still be a great option if we stopped here, but we’ve gone even further with optional configurations that make it easy for you to provide the right experience for your users.
Region Survivability
By default, CockroachDB provides zone-level survivability. However, for many companies, this does not meet their survival goals. As such, we’ve introduced the region-level survival goal that ensures your database will remain fully available for reads and writes, even if an entire region goes down. This added survival comes at a cost: write latency will be increased by at least as much as the round-trip time to the nearest region. Read performance will be unaffected. In other words, you are adding network hops and making writes slower in exchange for robustness.
You can configure a database to survive region failures using the ALTER DATABASE ... SURVIVE REGION FAILURE statement.
Table Locality
Every table in a multi-region database has a “table locality setting” applied to it. CockroachDB uses the table locality setting to determine how to optimize access to the table’s data from that locality. By default, all tables in a multi-region database are regional tables. That is, CockroachDB optimizes access to the table’s data from a single region (by default, the database’s primary region).
Regional tables provide low-latency reads and writes for an entire table from a single region. CockroachDB offers two additional table patterns for increased latency configurations:
- Regional by row tables are like regional tables, except different rows in the table can be optimized for access from different regions.
- Global tables are optimized for low-latency reads from all regions.
Regional by Row Tables
In regional by row tables, individual rows are optimized for access from different regions. This setting divides a table and all of its indexes into partitions, with each partition optimized for access from a different region. Like regional tables, regional by row tables are optimized for access from a single region. However, that region is specified at the row level in a hidden system column, instead of applying to the whole table.
Use regional by row tables when your application requires low-latency reads and writes at a row-level where individual rows are primarily accessed from a single region. For example, a user’s table in a global application may need to keep some users' data in specific regions due to regulations (such as GDPR) for better performance, or both.
Developers can shift a table from the default regional table to a regional by row table with a straightforward SQL statement:
ALTER TABLE ... SET LOCALITY REGIONAL BY ROW;
Regional by row tables come with even more enhanced autonomous behavior. We spoke above about how many legacy applications would require you to change your application to track globally unique identifiers like user id. CockroachDB can do this for you directly in the database without you having to change your application. CockroachDB will automatically store information about the user based on the region in which the request originated on any new insert to a regional by-row table. Even without the application passing region information to the database during an insert statement, we can see exactly the originating region of each request.
CockroachDB makes it easy to insert globally unique data, but what about reading it? How do we know which region to look for a user? We’ve enhanced our cost-based optimizer to automatically check the local region for any read before fanning out to check the other regions in parallel. If the data is in the local region, we can return a read in as little as 2 ms. If the data isn’t local, we will return the information with only the additional latency of the time it took to check the local region (2ms), which end-users will likely not notice. In most cases, CockroachDB can provide local inserts and local reads, on globally unique user infrastructure, all without you having to do anything.
Global Tables
Global tables optimize for low-latency reads from every region in the database by providing a new global transaction model. Any transaction reading from a global table receives consistent low-latency real-time information. In order to achieve optimized reads, we trade off increased write latencies from any given region since writes have to be replicated across every region to make the global low-latency reads possible. We have a separate upcoming post that will dive into more detail on this topic.
Use global tables when your application has a “read-mostly” table of reference data that is rarely updated and needs to be available to all regions.
Developers can shift a table from the default regional table to a global table with a straightforward SQL statement:
ALTER TABLE ... SET LOCALITY GLOBAL;
Use a Database Designed From Day One for Multi-Region Applications
Multi-region applications are significantly easier to build, manage, and deploy when powered by a database designed for a multi-region world. Many legacy databases find it very difficult, if not impossible, to bake multi-region into their existing capabilities. Even if they manage this feat, legacy databases lack the native low-latency optimizations built into CockroachDB’s cost-based optimizer and global transactions model.
CockroachDB makes multi-region configuration easy, enabling any developer to provide an improved user experience at scale.