When building a multi-region application, one of the first things to consider is how and where data will be placed. For example, when building a gambling application deployed across the country, you want to make sure users have quick access to their data no matter their location. Gamblers and the platforms they use both need low latency access to real-time data. It can make or break the user experience. This is an easy example because money is won and lost, but the requirement for applications to deliver low latency experiences to a global user base is obviously applicable to every other industry as well.
Traditionally, this work is left to the developer (you)! You must write code that understands how your multi-region deployment works, leading to a much more complex application than you’d build in a single-region deployment. If our gambling application needed to store user data in each region, we might have to deploy a database to all of our regions, meaning we’d have to keep track of which region a user belongs to and access the correct database accordingly.
In an ideal world, we’d like our database to handle this automatically (so that we don’t have to!). Instead of configuring multiple databases to store our users, we could simply have a single users table deployed across multiple regions! Each row in users could be homed independently to its region, allowing our application to retain the simplicity of a single-region application with the performance benefits of a multi-region application.
This type of data homing is called per-row homing, and it’s the basis for REGIONAL BY ROW tables in CockroachDB.
In this blog post, we’ll go over a few designs for a REGIONAL BY ROW table, and we’ll use the example of a gambling application to motivate why different designs might be appropriate in different situations.
Row-Level Data Homing Before REGIONAL BY ROW
Before CockroachDB version 21.1, in order to achieve row-level data homing, users had to configure table partitions. We won’t go into details here, but table partitions were difficult to use and inflexible. If you want to hear more, make sure to read our blog post on how we built REGIONAL BY ROW!
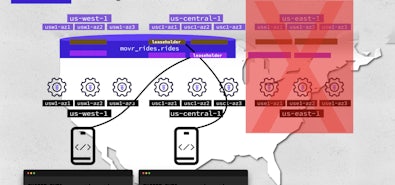
With the introduction of REGIONAL BY ROW, you can now simply add LOCALITY REGIONAL BY ROW to your table definitions and get automatic data homing based on the crdb_region column. For example, a user table for our gambling application might look like:
CREATE TABLE users (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
username STRING NOT NULL UNIQUE,
) LOCALITY REGIONAL BY ROW;
Note that here we don’t explicitly define the crdb_region column. If unspecified, CockroachDB will automatically add the column to any REGIONAL BY ROW table.
When inserting into this table, you can automatically insert into your local region by not specifying crdb_region or explicitly set a region:
-- If we're in us-east1, this will insert into us-east1.
INSERT INTO users (username) VALUES ('roach')
-- This will always insert into us-west1.
INSERT INTO users (username, crdb_region) VALUES ('roach2', "us-west1")
Auto-Rehoming in CockroachDB
Back in CockroachDB 21.2, we released an experimental auto-rehoming feature. This feature adds an ON UPDATE expression to crdb_region, updating crdb_region to the user’s gateway region whenever a row is updated.
Concretely, this means that an update to a row from us-east1 will set crdb_region for that row to us-east1.
-- Here we have a client in `us-east1` inserting a row into `us-west1`.
INSERT INTO users (username, crdb_region) VALUES ('roach', "us-west1")
SELECT (username, crdb_region) FROM users
+----------+-------------+
| username | crdb_region |
+----------+-------------+
| roach | us-west1 |
+----------+-------------+
-- After this UPDATE, the ON UPDATE expression will be evaluated, and the row will be homed into `us-east1`.
UPDATE users SET username = 'roach2' WHERE username = 'roach'
SELECT (username, crdb_region) FROM users
+----------+-------------+
| username | crdb_region |
+----------+-------------+
| roach2 | us-east1 |
+----------+-------------+
Multi-Region Application Experiments
Before using REGIONAL BY ROW, we want to test out a few different designs to see which will best fit our use case. To do this, we’ve designed some experiments that stress different performance characteristics of REGIONAL BY ROW.
In each of these experiments, we run a modified version of YCSB with support REGIONAL BY ROW tables. We run the experiments across 3 regions: us-east1, europe-west2, and asia-northeast1.
We configure clients with a “locality of access” value, corresponding to the percentage of operations accessing rows that were originally homed in the client’s local region. For example, 95% locality of access means that 95% of accesses will be in the local region whereas 5% of accesses will go to remote regions. In the plots, red corresponds to 100% locality, green to 95%, and yellow to 50%.
Reads and Updates
First, we test simple SELECT and UPDATEs across a table in 3 variants:
- Baseline - a table built with our manual partitioning primitives.
- Default - a standard
REGIONAL BY ROWtable. - Rehoming - a
REGIONAL BY ROWtable with auto-rehoming enabled.
For each of these table types, we run YCSB-B (95% reads, 5% updates).
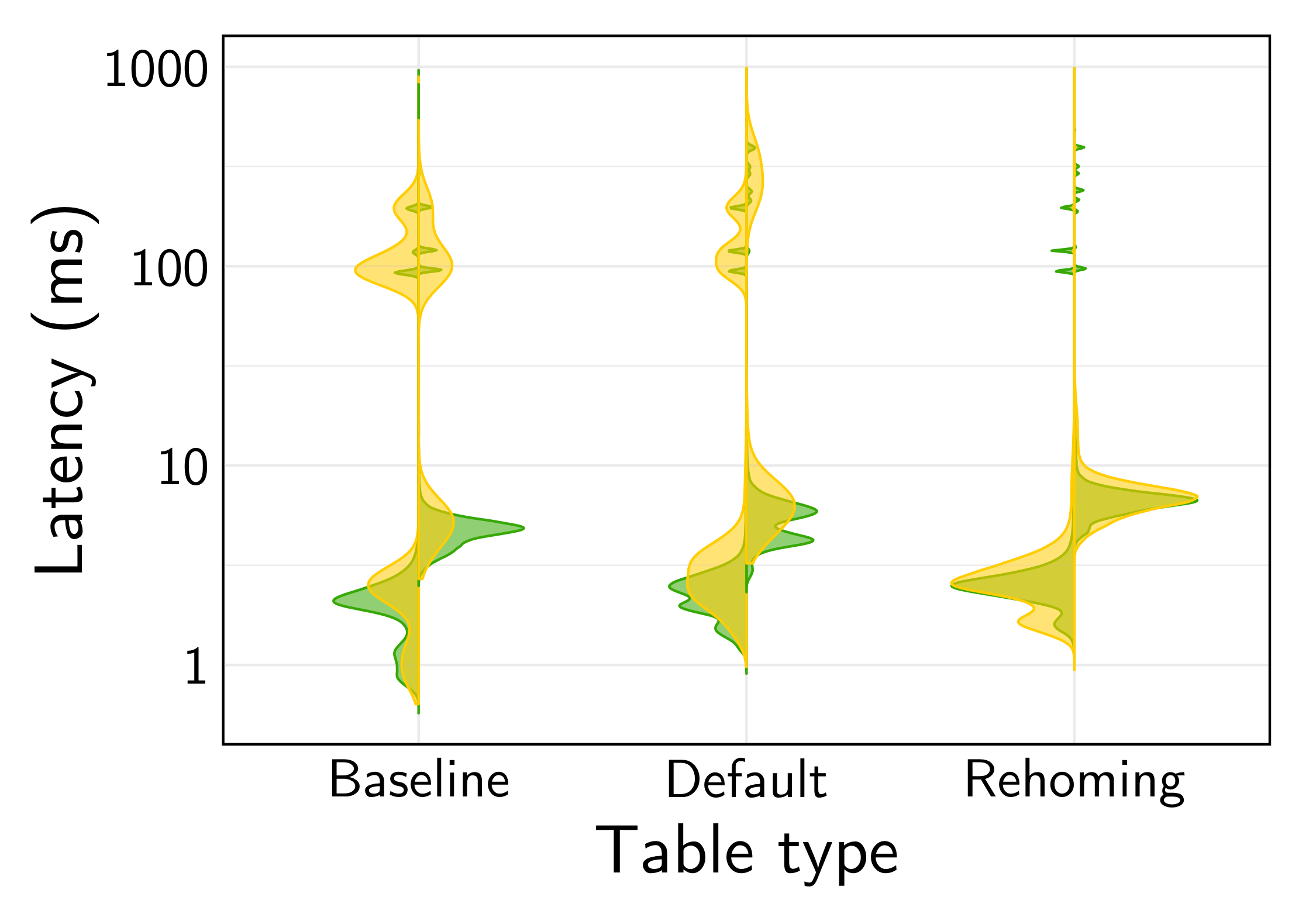
(Left is read latency, right is update latency)
In these results, Default maintains local latencies for both reads and writes, using Locality Optimized Search (LOS) to avoid region hops until necessary. It is only slightly slower than Baseline which can skip the local search step for remote accesses.
The Rehoming table gives us the best results, but we’ve plotted the ideal “uncontended” case here. See the rehoming section for more information on how contention impacts rehoming results.
As we can see, a default REGIONAL BY ROW table performs very similarly to a table built on our manual partitioning primitives, and our auto-rehoming table eventually achieves fully local latencies.
Locality Optimized Search
When setting up a REGIONAL BY ROW table, there are two primary types of crdb_region column to consider:
- Default
- Computed
With a default column, when a row is inserted, the value for crdb_region is manually specified. Subsequently, when a query is made against the row, the database will search for the row in two steps:
- Search the local region for the row
- If no row is found, search all remote regions.
This is called “locality optimized search”, and it’s what helps us achieve local query latency even if we don’t know a row is homed in the local region from the start.
If the crdb_region column is computed, we get a performance benefit similar to that of manually-partitioned tables: deterministic regions. If the computed column depends only on the information we query with, we deterministically know the value of crdb_region and therefore the row’s home region. This means we know which region to look for a row in, skipping locality optimized search.
A REGIONAL BY ROW bets table with a computed crdb_region for our gambling application might look like:
CREATE TABLE bets (
order_id STRING PRIMARY KEY,
region crdb_internal_region AS (
CASE
WHEN order_id LIKE 'us-east1-%' THEN "us-east1"
WHEN order_id LIKE 'us-central1-%' THEN "us-central1"
WHEN order_id LIKE 'us-west1-%' THEN "us-west1"
ELSE "us-east1"
END
),
user INT NOT NULL REFERENCES users (id)
) LOCALITY REGIONAL BY ROW AS region;
Here, a query like SELECT * WHERE order_id = 'us-east1-testorder' would be able to skip locality optimized search because the client can calculate the value for crdb_region based on order_id.
In practice, for SELECTs and UPDATEs, query times look pretty similar for both default and computed columns! We can also infer this behavior from the results in our first experiment. A table with computed crdb_region can skip locality optimized search, meaning it performs like our Baseline manually-partitioned table.
Inserts
In the read and update case, locality optimized search gets us good performance even when we don’t know the location of a particular row. In the case of an insert, however, this is not how it works.
When a row is inserted, the database must ensure that the insert does not violate the primary key uniqueness constraint. Therefore, it must query all regions for the primary key before inserting.
In the case of inserting into a table with the crdb_region column computed, however, the database can calculate in which region the row should be homed. Therefore, if you’re inserting into your local region, you can perform the insert without accessing any remote regions!
We see this below - latencies for inserting into a default REGIONAL BY ROW table are >100ms while latencies for a computed crdb_region column and a manually-partitioned table are on the order of tens of milliseconds. Note that there are 3 individual spikes in insert latency. These spikes correspond to a client in each region - because of the geographic placement, each client will have a slightly different latency required to complete the uniqueness check.
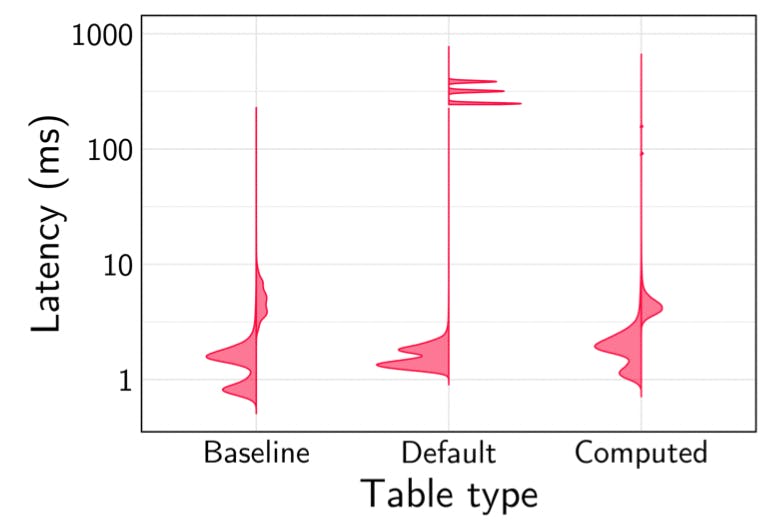
This performance advantage might be especially useful for our bets table. While a gambling application may not have a high number of users onboarding per second, they will have a high number of bets per second, creating a high insert load on the bets table.

Rehoming for better application performance
Finally, we want to test out how auto-rehoming could help our application perform better over time. This is particularly useful for our users table as when a user moves regions, we want their data to follow them.
For our users table, we could manually specify our region column with rehoming enabled as below:
CREATE TABLE users (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
username STRING NOT NULL UNIQUE,
region crdb_internal_region
DEFAULT default_to_database_primary_region(gateway_region())
ON UPDATE default_to_database_primary_region(gateway_region())
) LOCALITY REGIONAL BY ROW AS region;
If the user stays in the same region consistently, this strategy works great - the row is homed closer to them, and average latencies go down. However, if the row is being updated from multiple different regions, it will be thrashed around. This movement will negate any performance improvement from the rehoming, and the thrashing may even cause degraded performance.
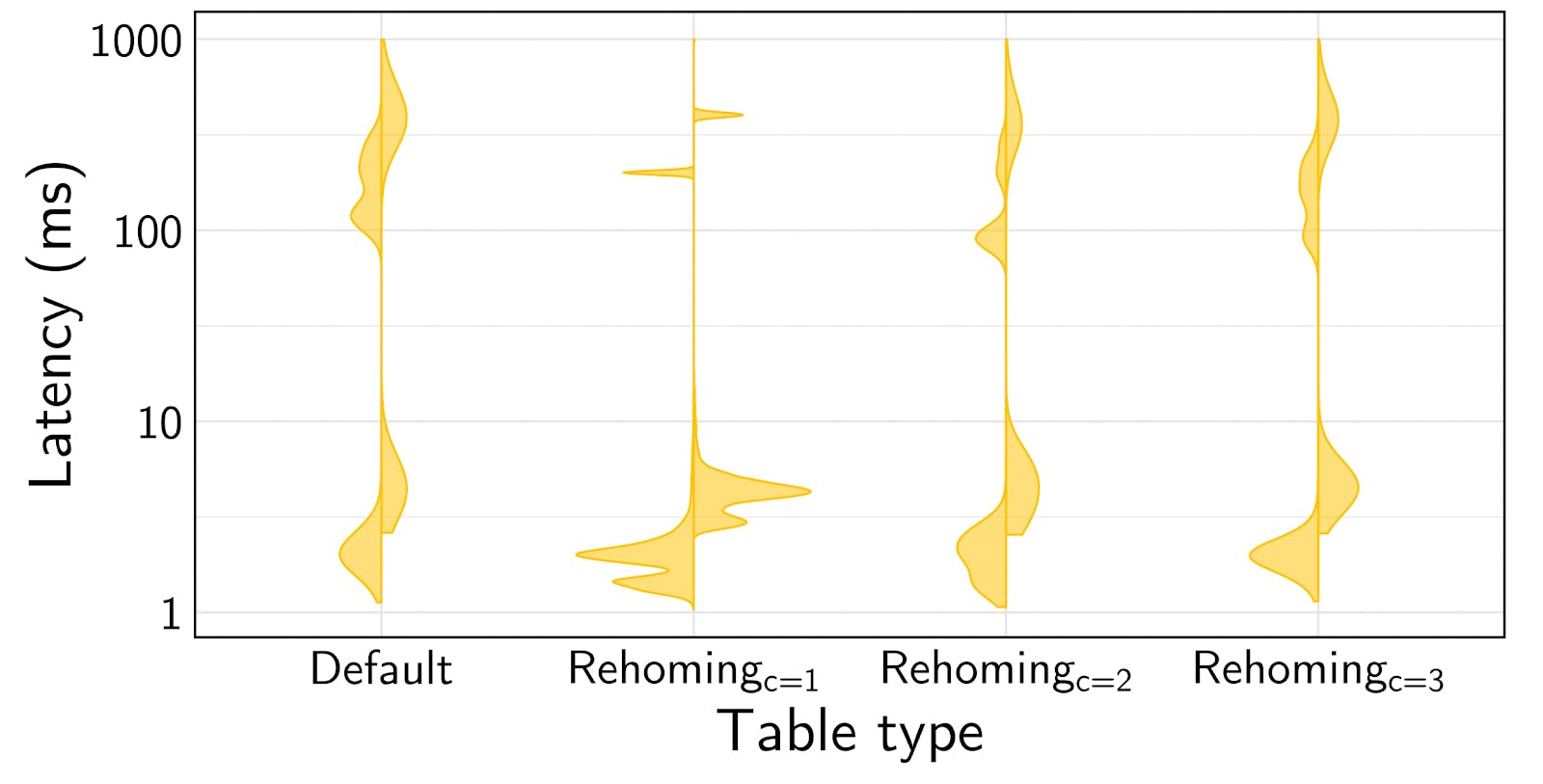
To evaluate automatic rehoming under contention, we run YCSB-B from all regions with 50% locality of access with all remote accesses targeting a shared range of keys. We vary the number of contending clients (c ={1,2,3}), and compare against Default where data is not re-homed.
When c = 3, cross-region contention is high as all clients are accessing a single keyspace. This means auto-rehoming will have little value as an UPDATE to a key doesn’t give any confidence that future accesses will come from the same region.
As cross-region contention decreases, however, auto-rehoming becomes more valuable. An UPDATE from a client gives more confidence that future accesses will come from that client. Particularly in the c = 1 case (zero cross-region contention), we see vastly improved performance over our Default table.
Try REGIONAL BY ROW in CockroachDB
REGIONAL BY ROW tables give us powerful control over our data’s location while also maintaining a single-table developer experience. When used properly, they can allow us great multi-region performance without many of the traditional headaches associated with multi-region deployments! Also, if you want to learn more you can check out our SIGMOD paper, that’s where I’ve pulled all of these graphs.
The best way to kick the tires on CockroachDB is to start with CockroachDB Serverless. It’s fast and free and will give you an instantaneous experience with the database. You could also spin it up yourself or take a look at CockroachDB Dedicated.
p.s. If you’re interested in joining us in making data easy, check out our careers page!